
监控服务
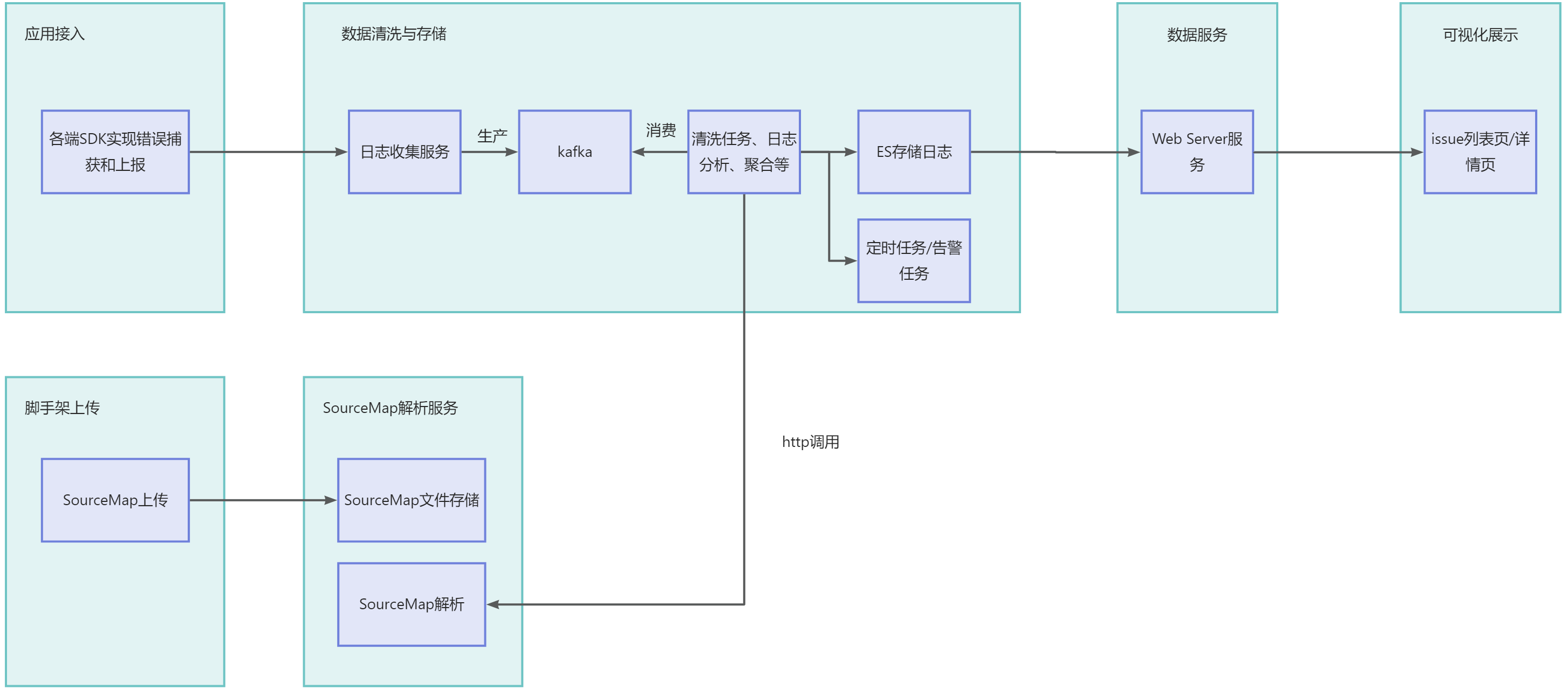
数据接入层
一般通过提供独立的日志服务器接收客户端日志,接收过程中,要对客户端日志内容的合法性、安全性等进行甄别,防止被人攻击。而且由于日志提交一般都比较频繁,多客户端同时并发的情况也常见。通过消息队列将日志信息逐一处理后写入到数据库进行保存也是比较常用的方案。
在这里客户端借助 SDK 上报监控数据指标,数据接入层接收相应数据,并做协议转换等简单处理后,作为生产者向 Kafka 写入数据。
- 解密上报的数据并验证其正确性;
- 加入一些客户端 SDK 无法拿到的字段:如 IP;
- 转发处理过后的数据。
为什么不是直接存入呢?
因为客户端上报的监控数据量和用户规模有关。如果直接入库,遇到高并发的时候,会因为服务器扛不住而导致数据丢失。与此同时,因为数据下游(数据的使用方,如数据清洗计算平台,监控预警模块)会有多个数据接收端,直接入库的话也会造成数据重复。
所以最好我们选择 Kafka,先让数据写进消息队列。Kafka 能通过缓存,慢慢接收这些数据,降低流量洪峰压力。同时,消息队列还有接收数据后将其删除的特点,可以避免数据重复的问题。
数据清洗层
| 方案 | 说明 | 缺点 | 优点 |
|---|---|---|---|
| File+Spark+Mysql+ELK | 由后端通过Spark清洗数据⼊库Mysql,通过Logstash定时同步Es,由Es进⾏聚合计算 | 流程冗⻓、数据断层、查询效率低、服务容易宕机 | 易上⼿、搭建成本低 |
| Kafka+Spark+ELK | Kafka取代⽂件读取,Spark清洗数据直接⼊库Es,Es进⾏聚合计算 | 指标数据开发受限、查询效率低、服务容易宕机 | 易上⼿、流程简化 |
| Kafka+Flink+ELK | Flink取代Spark清洗数据 | 不易上⼿、维护成本⾼、指标数据拓展性不够灵活 | 查询效率达到秒级、⾼并发不宕机 |
| Kafka+Flink+Clickhouse | ClickHouse取代ELK,Flink清洗明细数据,Clickhouse进⾏聚合计算 | 机器与集群维护压⼒⼤ | 查询效率达到毫秒级、数据拓展性强、成本下降 |
Kafka 是一个比较早的消息队列,但是它是一个非常稳定的消息队列,有着众多的用户群体。我们考虑 Kafka 作为我们消息中间件的主要原因如下:
- 高吞吐,低延迟:每秒几十万 QPS 且毫秒级延迟
- 高并发:支持数千客户端同时读写
- 容错性,可高性:支持数据备份,允许节点丢失
- 可扩展性:支持热扩展,不会影响当前线上业务
Apache Flink 是近年来越来越流行的一款开源大数据流式计算引擎,它同时支持了批处理和流处理,考虑 Flink 作为我们流式计算引擎的主要因素是:
- 高吞吐,低延迟,高性能
- 高度灵活的流式窗口
- 状态计算的 Exactly-once 语义
- 轻量级的容错机制
- 支持 EventTime 及乱序事件
- 流批统一引擎
获取IP地址
IP地址是按地域分布的,服务器获取到客户端IP后可以做流量统计和分析。
Node.js获取客户端IP
- X-Forwarded-For (RFC 7239)
通常 Server 端不会直接与 Client 端通信, 而是通过 Nginx 等代理接受客户端请求, 这时候 remoteAddress 是代理服务的地址, 无法描述客户端IP。
由此引入了HTTP 扩展协议头: X-Forwarded-For , 格式是:
X-Forwarded-For: client, proxy1, proxy2获取的时候取 X-Forwarded-For 的第一个 IP 地址即可,但需要注意的是: X-Forwarded-For 可伪造!
通常 Nginx 作为 proxy 时的配置:
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;- X-Real-IP
代理程序设置请求源的 IP 信息, 目前并不是 RFC 标准,X-Real-IP 不可伪造, 但仅能描述最近一个代理的真实IP, 如果有多级代理,仍旧不可作为真实客户端的 IP。
通常 Nginx 作为 proxy 时的配置:
proxy_set_header X-Real-IP $remote_addr;- req.socket.remoteAddress
在 Node.js 官方文档 net_socket_remoteaddress 中,我们得知可通过 req.socket.remtoeAddress 获取 Socket 连接的源 IP 地址信息。
根据官方文档 http_request_socket 的描述,req.connection 和 req.socket 是等价的,我们也可以通过 req.connection.remoteAddress 获取 Socket 连接的源 IP 信息。这种获取请求 IP 来源的方式,适用于客户端直连服务端的场景。
具体代码实现:
/**
* 获得请求发送方的 ip
* @param {Context} ctx
* @return {string}
*/
export function getIp(ctx) {
const xRealIp = ctx.get('X-Real-Ip');
const { ip } = ctx;
const { remoteAddress } = ctx.req.connection;
return xRealIp || ip || remoteAddress;
}Java服务获取真实IP
- X-Real-IP
nginx代理一般会加上此请求头。
- X-Forwarded-For
这是一个Squid开发的字段,只有在通过了HTTP代理或者负载均衡服务器时才会添加该项。
- Proxy-Client-IP 和 WL-Proxy-Client-IP
这个一般是经过apache http服务器的请求才会有,用apache http做代理时一般会加上Proxy-Client-IP请求头,而WL-Proxy-Client-IP是它的weblogic插件加上的头。
- HTTP_CLIENT_IP
有些代理服务器会加上此请求头。在网上搜了一下,有一个说法是:
- HTTP_X_FORWARDED_FOR
简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理(比如APACHE代理)或者负载均衡服务器时才会添加该项。它不是RFC中定义的标准请求头信息,在squid缓存代理服务器开发文档中可以找到该项的详细介绍。如果有该条信息, 说明您使用了代理服务器,地址就是后面的数值。可以伪造。标准格式如下:X-Forwarded-For: client1, proxy1, proxy2
public static String getIpAddress(HttpServletRequest request) {
String Xip = request.getHeader("X-Real-IP");
String XFor = request.getHeader("X-Forwarded-For");
if (!Strings.isNullOrEmpty(XFor) && !"unKnown".equalsIgnoreCase(XFor)) {
//多次反向代理后会有多个ip值,第一个ip才是真实ip
int index = XFor.indexOf(",");
if (index != -1) {
return XFor.substring(0, index);
} else {
return XFor;
}
}
XFor = Xip;
if (!Strings.isNullOrEmpty(XFor) && !"unKnown".equalsIgnoreCase(XFor)) {
return XFor;
}
if (Strings.nullToEmpty(XFor).trim().isEmpty() || "unknown".equalsIgnoreCase(XFor)) {
XFor = request.getHeader("Proxy-Client-IP");
}
if (Strings.nullToEmpty(XFor).trim().isEmpty() || "unknown".equalsIgnoreCase(XFor)) {
XFor = request.getHeader("WL-Proxy-Client-IP");
}
if (Strings.nullToEmpty(XFor).trim().isEmpty() || "unknown".equalsIgnoreCase(XFor)) {
XFor = request.getHeader("HTTP_CLIENT_IP");
}
if (Strings.nullToEmpty(XFor).trim().isEmpty() || "unknown".equalsIgnoreCase(XFor)) {
XFor = request.getHeader("HTTP_X_FORWARDED_FOR");
}
if (Strings.nullToEmpty(XFor).trim().isEmpty() || "unknown".equalsIgnoreCase(XFor)) {
XFor = request.getRemoteAddr();
}
return XFor;
}获取地理位置
当我们拿到客户端的公网IP后,就可以在页面直接查询对应IP的地理位置了,一般获取地理位置通过请求第三方接口来获取。这里我们通过一个开源库来获取。
- ip2region:有Java版本的,有Node.js版本的
UA解析
用户代理(User Agent,简称 UA),是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
注意
解析 UA 字符串并不总是准确,因为有些用户可能会篡改 UA 字符串。因此,在使用解析 UA 字符串获取访问者信息时,需要注意这些信息可能不准确。
平台获取UA有两种方式:
- 在JavaScript中,可以通过
navigator.userAgent获取到当前浏览器的UA字符串
const userAgent = navigator.userAgent;
console.log(userAgent)- 在服务器端,可以通过读取HTTP请求头中的
User-Agent来获取UA字符串。
获取到User-Agent之后,我们可以使用第三方库来解析 UA 字符串,例如 ua-parser-js 和 browscap-java。
使用 ua-parser-js 解析 UA 字符串示例代码如下:
const uaParser = require('ua-parser-js');
const parser = new uaParser();
const userAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36';
const result = parser.setUA(userAgent).getResult();
console.log(result);
/*
{
ua : "",
browser : {},
engine : {},
os : {},
device : {},
cpu : {}
}
*/解析UA后获取浏览器名称和版本,设备型号、类型、供应商,当前浏览器引擎名称和版本,正在运行的操作系统名称和版本, CPU 架构设计名称以及用户代理字符串。
SourceMap反解
这个过程主要依赖两个库:source-map 和 stacktracey,一个用于解析sourceMap 还原源码,另一个用于解析错误堆栈。
首先使用 stacktracey 解析错误堆栈,我们从错误堆栈中解析出了报错的文件以及代码的行列位置,其实就是异常堆栈中的编译后文件的文件名和行列号,我们甚至可以自己解析。下一步我们将基于这些信息去寻找报错的源码。
业界为我们提供了方便的SourceMap反解工具,利用Mozilla的source-map库进行反解
const sourceMap = require("source-map");
const fs = require("fs");
function parseSourceMap() {
// 此处替换为你下载下来的 sourcemap 文件
let data = fs.readFileSync("../index.js.5d59fc.js.map").toString();
const consumer = new sourceMap.SourceMapConsumer(data);
consumer.then(c => {
// 此处替换为原始报错的行列号
const line = 23,
column = 112003;
let s = c.originalPositionFor({ line, column });
console.log(s);
console.log(`origin code for line: ${line}, ${column}\n`);
console.log(
`======================================================================`
);
console.log(
c
.sourceContentFor(s.source)
.split("\n")
.slice(Math.max(s.line - 10, 0), s.line + 10)
.join(`\n`)
);
console.log(
`======================================================================`
);
});
}
module.exports = parseSourceMap;通过行号、列号以及SourceMap文件就可以将原始堆栈给反解出来,其实在线反解服务都是这么实现的。那么我们不可能在每次异常发生后再去反解,这样效率比较低,定位问题也比较慢。而线上部署代码也没有SourceMap文件的,有的话相当于把源码暴露给别人看了。
实际的解决方案是,利用各种打包插件或二进制工具在构建过程中将生成的SourceMap直接上传到服务端,上传完成后再删除SourceMap文件再去部署上线。
Sentry这款产品就有对应的上传插件,我们可以自定义一个webpack插件,只需配置应用ID、SourceMap路径和版本就可以。用户在发版构建时就可以完成SourceMap的上传工作,而异常发生后,就可以在清洗存储时通过反解服务自动完成解析,不需要用户再关心反解等相关工作了。
异常聚合
通过SourceMap我们将异常错误解析成原始堆栈,但是大部分错误是有相似性的,这势必就要提到异常聚合这个关键问题。当当提到大部分错误是有相似性的,当用户量大的时候同一个错误可能会被上报上万次,如果我们上报一条存一条,并且展示给用户一条错误,那么平台侧错误列表会被重复的错误占满,这样的展示毫无意义,毕竟一个错误展示上千次还是一个错误。这种情况下,我们需要对错误进行分组和聚合,将具有相同特征的错误,归类为一种错误,并且只对用户暴露这种聚合后的错误列表,但是也会以小图展示错误数以及影响用户数。
那么聚合的逻辑是什么?怎么样聚合效果最好呢?
我们先观察一下JS错误所携带的信息,name错误类型、message错误信息、stack错误堆栈、filename文件名、columnNumber列号、lineNumber行号。这样聚合方案就出来了,利用某种方式将error的相关信息提取为fingerprint,每一次上报如果是相同的fingerprint那就归为一类,问题可以进一步细化为使用哪些字段聚合,如何生成指纹才尽可能准确。首先错误抛出的文件名和行列号没必要使用,有name和message我们就知道错误是什么,如果使用name和message聚合粒度太粗,这里参考了SENTRY的聚合策略,将反解后的堆栈进一步拆解为frame,每个frame包含调用文件名(filename),调用函数名(function)和当前代码行(context line)。
interface GroupingComponent{
contributes: boolean,
values: (GroupingComponents|string)[],
id: | 'exception'|'type'|'value'|'stacktrace'|'frame'|'function'|'contextline'|'filename'
}将错误信息转化为GroupComponent对象,当堆栈反解完毕后自上而下递归检测,并且自下而上的生成一个个的嵌套GroupingComponent,最后再调用顶层的一个生成hash的方法,得到最终的一个hash值。
不参与hash计算的部分case:
- 递归调用:当前frame与前一frame的filename、function、lineNumber、colNumber都一样
- 匿名路径:function为eval或
filename in["[native code]","native code","eval code","<anonymous>"]或者不为JS文件 - 计算开销过大:
contextLine.length>120 - 匿名函数:
function in ["?","<anonymous function>","<anonymous>","Anonymous function"]等
处理人分配
当将JS错误聚合展示消费后,需要让研发快速跟进修复,以提高站点的稳定性,如果是手动分配,会存在很大的局限性,需要有人定期巡检才行。如果能做到谁写得代码出现JS错误自动分配给谁,那么用起来就很舒适。
一般公司会用Gitlab/Github作为代码的远端仓库,而这些平台提供了丰富的api,协助用户做blame。通过api可以获取到目标文件每一行历史的所有作者信息。当我们通过SoureMap反解到堆栈信息后,通过open-api获取blame历史,我们就可以确定每一行的作者究竟是谁,从而将异常分配给他。
通过Git blame找到出错行的作者
git blame -L <range> <file>我们需要几个信息
- 线上报错的项目对应的源代码仓库名,如 toutiao-fe/slardar
- 线上报错的代码发生的版本,以及与此版本关联的 git commit 信息,为什么需要这些信息呢?
默认用来 blame 的文件都是最新版本,但线上跑的不一定是最新版本的代码。不同版本的代码可能发生行的变动,从而影响实际代码的行号。如果我们无法将线上版本和用来 blame 的文件划分在统一范围内,则很有可能自动定位失败。
因此,我们必须找到一种方法,确定当前 blame 的文件和线上报错的文件处于同一版本。并且可以直接通过版本定位到关联的源代码 commit 起止位置。这样的操作在 Sentry 的官方工具 Sentry-Cli 中亦有提供。
通过 相关的 二进制工具,在代码发布前的脚本中提供当前将要发布的项目的版本和关联的代码仓库信息。同时在数据采集侧也携带相同的版本,线上异常发生后,我们就可以通过线上报错的版本找到原始文件对应的版本,从而精确定位到需要哪个时期的文件了。