
压缩&合并
我们大家都知道前端要想展示页面,需要很多相关的资源文件,例如HTML、CSS、JS文件及图片等资源文件,只有所需的资源被浏览器请求到后,通过渲染阶段才能达到期待的页面效果。那么如何快速的请求到资源就是一个优化点,比如能否压缩请求资源的大小,是否能将请求资源进行合并以减少HTTP请求的数量。那么本篇文章讲解对于资源的合并与压缩来进行优化。
前端资源压缩与合并
首先我们需要知道浏览器的请求从发送到返回都经历了什么?这样我们可以从链路中将请求的时间缩短,从而加快web前端访问速度,提升性能。
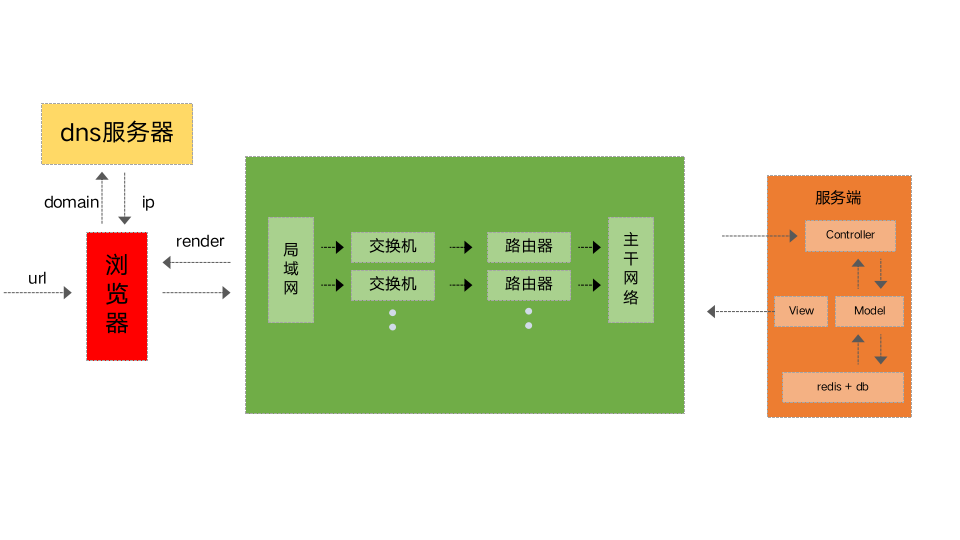
以上是用户输入请求的一个过程,我们向浏览器输入URL,浏览器会将URL进行拆分解析,将域名发送给DNS服务器,DNS会返回域名对应的IP地址,将IP地址返回给浏览器,然后把IP地址以及请求参数放在协议中发送到网络中,经过局域网、交换机、路由器和主干网络发送到服务端,服务端会将渲染好的页面返回给网络,这时候一个请求的response就从服务端返回到浏览器中,浏览器主要做一个render的过程,主要将服务器返回的html以及相关的css、js去进行渲染,在渲染的过程中浏览器会生成相关的dom树以及对应的css树,将dom树和css树进行整合就可以知道dom节点最终渲染的样式,样式渲染完成后,浏览器会去执行JS相关的脚本,最终页面展现出来。
从以上请求流程中我们可以找到性能优化点:
- dns是否可以通过缓存减少dns查询时间?
- 网络请求的过程走最近的网络环境?
- 相同的静态资源是否可以缓存?
- 能否减少http请求大小?
- 减少http请求
- 服务端渲染
其实深入理解http请求的过程是前端性能优化的核心。
前端资源的压缩与合并主要包括减少HTTP的请求数量和减少HTTP请求资源的大小。以下具体介绍相关的内容。
html压缩
HTML的全称是超文本标记语言,HTML网页本身是一种文本文件,通过在文件中添加标记符,可以告诉浏览器如何显示其中的内容,包括文字大小,颜色,图片显示等等。这就意味着在文本文件中的一些特定意义的字符可以在浏览器显示的时候就不一样了,HTML代码压缩就是压缩这些在文本文件中有意义,但是在HTML中不显示的字符,包括空格,制表符,换行符等,还有一些其他意义的字符,如HTML注释也可以被压缩。这些字符在我们写代码中是有意义的,可以保持很好的代码风格,但是对于浏览器解析是没有意义的,所以我们在生产环境中可以对其进行压缩。
压缩工具:
- 使用在线网站进行压缩(不使用)
- nodejs提供了html-minifier工具
- 后端模板引擎渲染压缩
CSS压缩
CSS压缩主要是无效代码的删除(例如注释、无效字符)、CSS语义合并(有可能语义重复)。
压缩工具:
- 使用在线网站进行压缩(不使用)
- 使用html-minifier对html中的css进行压缩
- 使用clean-css对css进行压缩
JS压缩与混淆
JS压缩主要包括无效字符的剔除、注释的剔除、代码语义的缩减与优化、代码混淆保护。
压缩工具
- 使用在线网站进行压缩(不使用)
- 使用html-minifier对html中的js进行压缩
- 使用uglifyjs2对js进行压缩
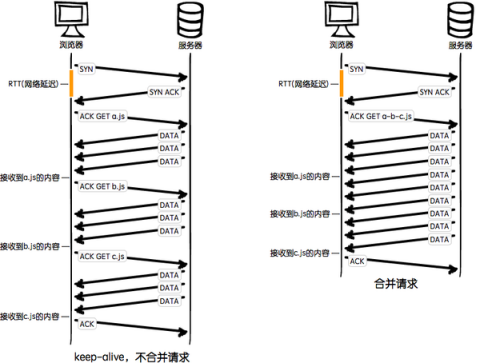
不合并请求有以下缺点:
- 文件与文件之间有插入的上行请求,增加了n-1个网络延迟,n是总共要请求的文件数量。
- 收到网络丢包的影响更严重,因为每一次的网络请求都有一定概率的丢包可能。
- keep-alive方式本身也存在一些问题,请求在经过代理服务器时连接有可能会断开,它很难保持keep-alive在整个请求过程中的状态。
合并请求有以下缺点:
- 首屏渲染问题:当经过合并后的JavaScript文件非常大且请求时间比较久时,页面渲染过程就会有延迟。
- 缓存失效问题:因为大部分项目都有缓存策略,即每个请求的js文件都会加一个md5的戳,用来标识文件是否发生修改更新,当发现文件被修改时,就会让缓存失效重新请求文件。如果源文件有一处小的修改,在文件合并中,就会造成大面积的缓存失效。
综合考虑文件合并策略:
- 公共库合并:通常我们的前端代码会包含业务逻辑代码和引用的第三方公共库代码,业务逻辑代码更改频繁,所以可以将公共库代码打包成一个文件,对业务代码进行单独处理。
- 不同页面的合并:大部分前端都是单页应用,我们希望单页应用的不同页面被路由请求到后,才去加载对应页面的JS文件及相关资源,这就需要对不同页面的文件进行单独打包。
- 了解文件合并的优缺点之后,可以根据项目的情况见机行事随机应变。
文件合并工具:
- 使用在线网站进行文件合并(不使用)
- 使用nodejs进行文件合并(构建工具gulp、webpack)