
高质量代码
软件工程师日常工作主要就是写代码,工作产出也是代码。代码是我们的一张亮,能写出高质量的代码,本身就应该是我们自己对自己的要求。
对于企业来讲,更希望能招聘到产出高质量代码的员工。企业的软件产品都是多个程序员合作写出来的,如果一旦有一位程序员产出代码质量不高,则会严重影响整个软件产品的质量。
很多同学面试完了之后,觉得自己写的代码也都对,正常执行也都没问题。但是最后面试没有通过,就很纳闷,觉得自己非技 术方面有问题。其实不然,也许是你的代码是对的,但质量不高。
能在规定时间内写出功能健全、思路清晰、格式规整的代码,这是前端工程师的必备技能,所以面试时必考手写代码。
为何要考察
代码是成员的一张脸。如果代码都写不好,那不具备基本的工作能力。所以,面试都要考察手写代码。
而且,实际工作中,多人协同做项目,你自己写不好代码,会影响整个项目。所以,代码写不好,工作找不到。
考察重点
- 代码规范性:符合代码规范,逻辑清晰可读
- 功能完整性:考虑全面所有功能
- 鲁棒性:处理异常输入和边界情况
规范性
记得前些年和一位同事(也是资深面试官)聊天时,他说到:一个候选人写完了代码,不用去执行,你打眼一看就知道他水平 怎样。看写的是不是整洁、规范、易读,好的代码应该是简洁漂亮的,应该能明显的表达出人的思路。
代码规范性,包括两部分。
- 第一,就是我们日常用 eslint 配置的规则。例如用单引号还是双引号,哪里应该有空格,行尾是否有分号等。这些是可以统一 规定的。
- 第二,就是代码可读性和逻辑清晰性。 例如变量、函数的命名应该有语义,不能随便 x1 x2 这样命名。
再例如,一个函数超过 100 行代码就应该拆分一下,否则不易读。
再例如,一段代码如果被多个地方使用,应该抽离为一个函数,复用。像这些是 eslint 无法统一规定的,需要我们程序员去判断和优化。 再例如,在难懂的地方加注释。
PS:发现很多同学写英文单词经常写错,这是一个大问题。可以使用一些工具来做提醒,例如 vscodespellchecker。
完整性
代码功能要完整,不能顾头不顾尾。例如,让你找到 DOM 节点子元素,结果只返回了 Element ,没有返回 Text 和 Comment 。 要保证代码的完整性,需要两个要素。
- 第一,要有这个意识,并且去刻意学习、练习。
- 第二,需要全面了解代码操作对象的完 整数据结构,不能只看常用的部分,忽略其他部分。
鲁棒性
鲁“鲁棒”是英文 Robust 的音译,意思是强壮的、耐用的。即,不能轻易出错,要兼容一些意外情况。
例如你定义了一个函数 function ajax(url, callback) {...} ,我这样调用 ajax('xxx', 100) 可能就会报错。因为 100 并不 是函数,它要当作函数执行会报错的。
再例如,一些处理数字的算法,要考虑数字的最大值、最小值,考虑数字是 0 或者负数。在例如,想要通过 url 传递一些数 据,要考虑 url 的最大长度限制,以及浏览器差异。
PS:使用 Typescript 可以有效的避免类型问题,是鲁棒性的有效方式。
数组扁平化(一级)
题目是写一个JS 函数,实现数组扁平化,只减少一级嵌套。如输入[1,[2,[3]],4],输出[1,2,[3],4]。
思路是:
- 定义空数组 arr= [],遍历当前数组。
- 如果 item 非数组,则累加到 arr
- 如果 item 是数组,则遍历之后累加到 arr
export function flattern1(arr){
const res = [];
arr.forEach(item=>{
if(Array.isArray(item)){
item.forEach(n=>res.push(n));
}else{
res.push(item);
}
});
return res
}
export function flattern2(arr){
const res = [];
arr.forEach(item=>{
res=res.concat(item)
});
return res
}数组扁平化(深度)
题目:写一个 JS 函数,实现数组扁平化,减少所有嵌套的层级。如输入[1,[2,[3]],4],输出[1,2,3,4]。
思路:先实现一级扁平化,然后递归调用,直到全部扁平。
export function flattenDeep1(arr){
const res = [];
arr.forEach(item=>{
if(Array.isArray(item)){
const flatItem = flattenDeep1(item)
flatItem.forEach(n=>res.push(n));
}else{
res.push(item)
}
});
}
export function flattenDeep2(arr){
const res = [];
arr.forEach(item=>{
if(Array.isArray(item)){
const flatItem = flattenDeep2(item)
res = res.concat(flatItem);
}else{
res.push(item)
}
});
}获取类型
手写一个 getType 函数,传入任意变量,可准确获取类型。如 number、string、boolean 等值类型,还有 object、array、map、regexp 等引用类型。
常见的类型判断有:
- typeof:只能判断值类型,其他就是 function 和 object
- instanceof:需要两个参数来判断,而不是获取类型
例如下面使用枚举,容易忽略某些类型。增加了新类型,需要修改代码。
export function getType(x){
//通过 typeof 判断值类型和 function
//其余的'object'通过 instanceof 枚举
if(typeof x === 'object'){
if(x instanceof Array) return 'array'
if(x instanceof Map) return 'map'
//很多....
return 'object'
}
}应该使用 Object.prototype.toString.call(x),注意,不能直接调用 x.toString()。
export function getType(x){
const originType = Object.prototype.toString.call(x) // '[object String]'
const spaceIndex = originType.indexOf(' ')
const type = originType.slice(spaceIndex + 1,-1) // 'String'
return type.toLowerCase();
}new一个对象发生了什么?请手写代码表示
class Foo{
//属性
name:string
city:string
constructor(name:string){
this.name = name;
this.city = '北京'
}
getName(){
return this.name
}
}
function Foo(name){
this.name = name
this.city = '北京'
}
Foo.prototype.getName = function (){ return this.name }class 是 Function 的语法糖。
- 创建一个空对象 obj,继承构造函数的原型
- 执行构造函数(将 obj 作为 this)
- 返回 obj
export function customNew<T>(constructor:Function,...args:any[]):T{
//1.创建一个空对象,继承 constructor 的原型
const obj = new Object.create(constructor.prototype)
//2.将 obj 作为 this,执行 constructor,传入参数
constructor.apply(obj,args)
//3.返回 obj
return obj
}深度优先遍历 DOM 树,结果会输出什么?
给一个 DOM 树,深度优先遍历会输出什么?
例如有下面一个 DOM 树。
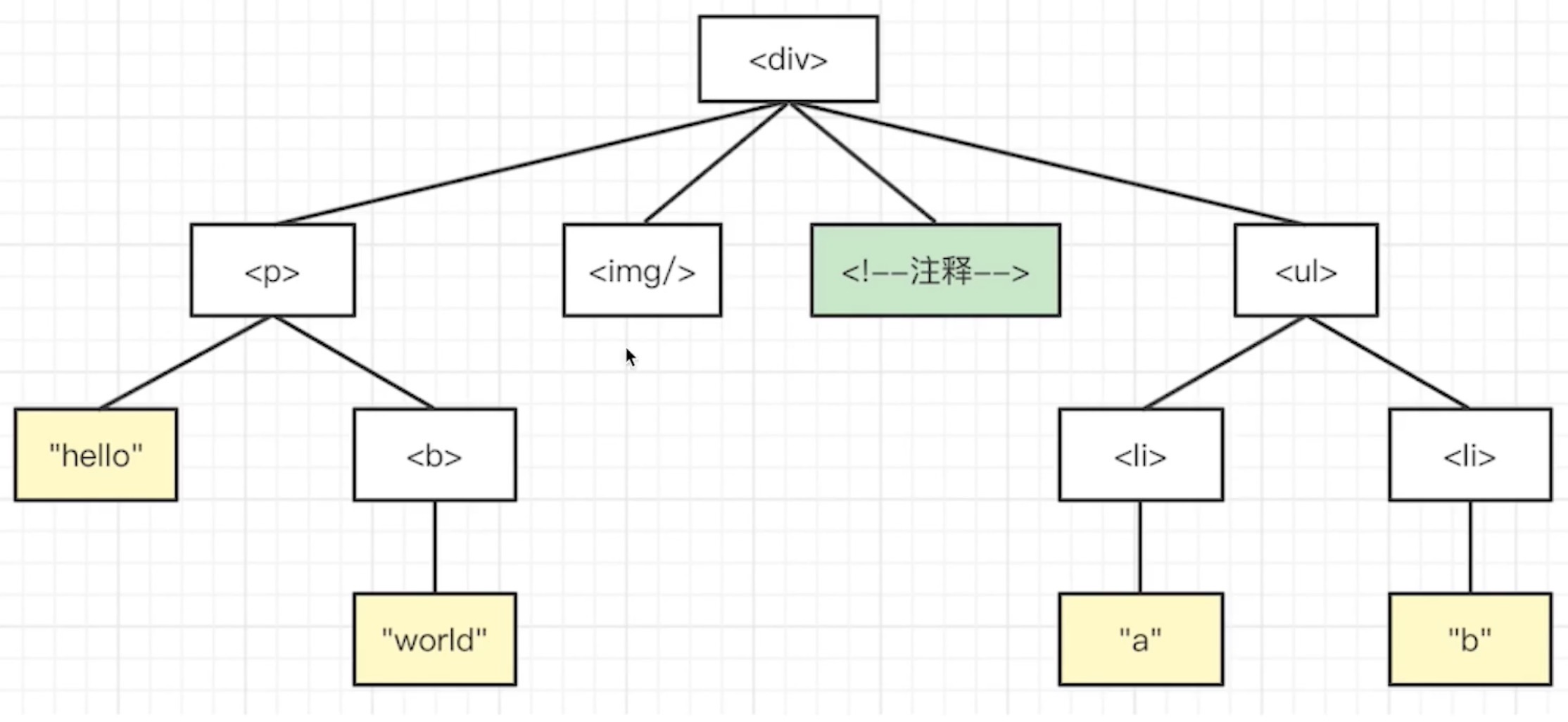
深度优先就是先从 root 根节点开始,以深度为主。
function visitNode(node){
if(node instanceof Comment){
//注释节点
console.info(node.textContent)
}
if(node instanceof Text){
//文本节点
console.info(node.textContent.trim())
}
if(node instanceof HTMLElement){
//元素节点
console.info(node.tagName.toLowerCase())
}
}
function depthFirstTraverse(root){
visitNode(root)
const childNodes = root.childNodes; //.childNodes和.children不一样
if(childNodes.length){
childNodes.forEach(child=>{
depthFirstTraverse(child) //递归
});
}
}深度优先,递归,贪心
广度优先遍历 DOM 树,结果会输出什么?
给一个 DOM 树,广度优先遍历会输出什么?
例如有下面一个 DOM 树。
深度优先就是先从 root 根节点开始,以横向广度为主。
function visitNode(node){
if(node instanceof Comment){
//注释节点
console.info(node.textContent)
}
if(node instanceof Text){
//文本节点
console.info(node.textContent.trim())
}
if(node instanceof HTMLElement){
//元素节点
console.info(node.tagName.toLowerCase())
}
}
function breadthFirstTraverse(root){
const queue = [];
//根节点入队列
queue.unshift(root)
while(queue.length>0){
const curNode = queue.pop()
if(curNode == null) break;
visitNode(curNode)
//子节点入队
const childNodes = curNode.childNodes;
if(childNodes.length){
childNodes.forEach(child=>queue.unshift(child));
}
}
}广度优先,使用队列。
深度优先遍历可以不用递归吗?
可以不用递归,用栈。因为递归本身就是栈。
function visitNode(node){
if(node instanceof Comment){
//注释节点
console.info(node.textContent)
}
if(node instanceof Text){
//文本节点
console.info(node.textContent.trim())
}
if(node instanceof HTMLElement){
//元素节点
console.info(node.tagName.toLowerCase())
}
}
function depthFirstTraverse(root){
const stack = [];
//根节点压栈
stack.push(root)
while(stack.length>0){
const curNode = stack.pop();
if(curNode == null) break;
visitNode(curNode);
//子节点压栈
const childNodes = curNode.childNodes;
if(childNodes.length>0){
Array.from(childNodes).reverse().forEach(child=>stack.push(child))
}
}
}- 递归:逻辑更加清晰,但容易发生stack overflow错误
- 非递归:效率更高,但逻辑比较复杂
手写 LazyMan
LazyMan 是一个 JavaScript 库,它允许你以链式调用的方式来编写异步代码。
- 支持 sleep 和eat 两个方法
- 支持链式调用
代码设计:
- 由于有 sleep功能,函数不能在调用时触发。
- 初始化一个列表,把函数注册进去。
- 由每个 item 触发 next 执行(遇到 sleep 则异步触发)
class LazyMan{
private name: string;
private tasks: Function[]= [];//任务列表
constructor(name:string){
this.name = name;
setTimeout(()=>{
this.next();
})
}
eat(food:string){
const task = ()=>{
console.log(`${this.name} eat ${food}`);
//立刻执行下一个
this.next();
}
this.tasks.push(task);
return this;
}
private next(){
const task = this.tasks.shift(); //取出当前 tasks 的第一个任务
if(task) task()
}
sleep(seconds:number){
const task = ()=>{
setTimeout(()=>{
this.next();
},seconds*1000);
}
this.tasks.push(task);
return this;
}
}手写一个函数,把其他函数柯里化
- curry 返回的是一个函数
- 执行 fn,中间状态返回函数,如 add(1)或者 add(1)(2)
- 最后返回执行结果,如 add(1)(2)(3)
function curry(fn:Function){
const fnArgsLength = fn.length; //传入函数的参数长度
let args:any[] = [];
//ts 中独立的函数,this 需要声明类型
function calc(this:any,...newArgs:any[]){
//积累参数
args = [...args,...newArgs];
if(args.length<fnArgsLength){
//参数不够,返回函数
return calc;
}else{
//参数够了,返回执行结果
return fn.apply(this, args.slice(0,fnArgsLength));
}
}
return calc;
}
function add(a:number,b:number,c:number){
return a+b+c;
}
const curryAdd = curry(add)
curryAdd(10)(20)(30)instanceof 原理是什么,请用代码表示
例如f instanceof Foo,顺着f.__proto__向上查找(原型链),看能否找到Foo.prototype
function myInstanceof(instance:any, origin:any): boolean{
if(instance == null) return false; //null undefined
const type = typeof instance;
if(type!=="object" && type!=="function"){
//值类型
return false;
}
let tempInstance = instance;//为了防止修改instance
while(tempInstance){
if(tempInstance.__proto__=== origin.prototype){
return true; //匹配上了
}
//未匹配上
tempInstance = tempInstance.__proto__; //顺着原型链往上找
}
return false;
}手写函数 bind
bind 是返回一个新函数,但是不执行。绑定 this 和部分参数,如果是箭头函数,无法改变 this,只能改变参数。
Function.prototype.customBind = function(context:any,...bindArgs:any[]){
//context 是 bind 传入的 this
//bindArgs 是 bind传入的各个参数
const self = this; //当前的函数本身
return function (...args:any[]){
//拼接参数
const newArgs = bindArgs.concat(args);
return self.apply(context,newArgs);
}
}手写函数 call 和 apply
bind返回一个新函数(不执行),call和apply会立即执行函数。绑定this,传入执行参数。
Function.prototype.customCall = function(context:any,...args:any[]){
if(context == null){
context = globalThis;
}
if(typeof context !== 'object') context = new Object(context) //值类型变为对象
const key = symbol(); //不会出现属性名称的污染
context[key] = this; //this就是当前的函数
const res = context[key](...args); //绑定了this
delete context[key];
return this;
}
Function.prototype.customApply = function(context:any,args:any[]=[]){
if(context == null){
context = globalThis;
}
if(typeof context !== 'object') context = new Object(context) //值类型变为对象
const key = symbol(); //不会出现属性名称的污染
context[key] = this; //this就是当前的函数
const res = context[key](...args); //绑定了this
delete context[key];
return this;
}手写EventBus
首先EventBus有on、once、emit、off,我们分析这几个函数的作用:
- on和once注册函数,存储起来
- emit时找到对象的函数,执行
- off找对应的函数,从对象中删除
注意区分on和once
- on绑定的事件可以连续执行,除非off
- once绑定的函数emit一次即删除,也可以未执行而被off
- 数据结构上标识出on和once
class EventBus{
private events: {
[key:string]:Array<{fn:Function;isOnce:boolean}>
}
constructor(){
this.events = {}
}
on(type: string, fn: Function,isOnce: boolean = false){
const events = this.events;
if(events[type]==null){
events[type] = []; //初始化Key的fn数组
}
events[type].push({fn,isOnce});
}
once(type: string, fn: Function){
this.on(type,fn,true);
}
off(type:string,fn?:Function){
if(!fn){
//解绑所有的type函数
this.events[type] = [];
}else{
//解绑单个fn
const fnList = this.events[type];
if(fnList){
this.events[type] = fnList.filter(item=>item.fn!==fn)
}
}
}
emit(type:string, ...args:any[]){
const fnList = this.events[type];
if(fnList==null)return;
this.events[type] = fnList.filter(item=>{
const { fn, isOnce } = item;
fn(...args);
//once执行一次就要被过滤掉
if(!isOnce) return true;
return false;
});
}
}用JS实现一个LRU缓存
LRU即Least Recently Used最近使用,如果内存使用,只缓存最近使用的,删除沉水数据。它有两个核心API:get和set。
- 首先用哈希表存储数据,这样get、set才够快O(1)
- 必须是有序的,常用数据放在前面,“陈述”数据放在后面
- 哈希表+有序,就是Map---其他都不行
class LRUCache{
private length:number;
private data: Map<any,any> = new Map()
constructor(length:number){
if(length<1) throw new Error('invalid length')
this.length = length;
}
set(key:any,value:any){
const data = this.data;
if(data.has(key)){
data.delete(key);
}
data.set(key,value)
if(data.size>length){
//如果超出了容量,则删除Map中最老的元素
const delKey = data.keys().next().value;
data.delete(delKey)
}
}
get(key:any){
const data = this.data;
if(!data.has(key)) return null
const value = data.get(key)
data.delete(key)
data.set(key,value)
return value;
}
}手写一个深拷贝函数,考虑Map、Set,循环引用
最简单的深拷贝使用JSON.stringify和parse,但是它无法转换函数,无法转换Map、Set,无法转换循环引用。
如果你的数据结构是简单的数字、字符串,那么用JSON.stringify相对合适一下。
普通深拷贝,只考虑Object、Array,无法转换Map、Set和循环引用。
/**
* obj obj
* weakmap 为了避免循环引用,用weakmap不会导致内存泄露
*/
export function cloneDeep(obj:any,map=new WeakMap()):any{
if(typeof obj!=='object' && obj == null) return;
//避免循环引用,不用重新计算
const objFromMap = map.get(obj);
if(objFromMap) return objFromMap;
let target:any = {};
map.set(obj,target);
//Map
if(obj instanceof Map){
target = new Map();
obj.forEach((v,k)=>{
const v1 = cloneDeep(v,map);
const k1 = cloneDeep(k,map);
target.set(k1,v1);
})
}
//Set
if(obj instanceof Set){
target = new Set();
obj.forEach(v=>{
const v1 = cloneDeep(v,map);
target.add(v1);
})
}
//Array
if(obj instanceof Array){
target = obj.map(item=>cloneDeep(item,map))
}
//Object
for(const key in obj){
const val = obj[key];
const val1 = cloneDeep(val,map);
target[key] = val1;
}
return target;
}