
编译原理
Babel 简介
Babel 是 JavaScript 编译器(来自官网描述)。它将高版本 ECMAScript 语法编译为浏览器都支持的 ES5 语法。
Babel 毫无疑问是目前前端极其重要的基础设施之一了,在介绍 Babel 之前,我们简要梳理下 JavaScript 发展史。
JavaScript 发展简史
- 1990 年底,万维网(WWW)诞生,可以在命令行查看网页。但通过命令行看网页,也是不太方便的。
- 1992 年底,美国国家超级电脑应用中心(NCSA)开始开发一个独立的浏览器,叫做 Mosaic。这是人类历史上第一个浏览器,从此网页可以在图形界面的窗口浏览。
- 1994 年 10 月,Mosaic 通信公司成立,不久后改名为 Netscape,其主要开发面向普通用户的新一代浏览器 Netscape Navigator。
- 1994 年 12 月,Netscape Navigator 发布了 1.0 版。该版本很受欢迎,但缺乏一种脚本语言,用于控制浏览器的行为。
- 1995 年,程序员 Brendan Eich 受雇于 Netscape 公司,只用了 10 天就开发出 JavaScript 1.0 版本,当时命名为 Mocha,1995 年 9 月改名为 LiveScript。
- 1995 年 12 月,Netscape 公司与 Sun 公司(Java语言的发明者和所有者)达成协议,后者允许将 LiveScript 叫做 JavaScript。对于两个公司而言都有益处:NetScape 公司可以借助 Java 的声势,而 Sun 公司则将自己的影响力扩展到了浏览器。
- 1996 年 3 月,Navigator 2.0 浏览器正式内置了 JavaScript 脚本语言。
- 1996 年 8 月,微软模仿 JavaScript 开发了一种相近的语言,取名为 JScript,首先内置于 IE3.0。
- 1996 年 11 月,Netscape 公司决定将 JavaScript 提交给国际标准化组织 ECMA(European Computer Manufacturers Association),希望 JavaScript 能够成为国际标准,以此抵抗微软。
- 1997 年 7 月,ECMAScript 1.0 版发布。ECMA 组织发布 262 号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript。由于 ECMA 的开放和中立性,ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的实现。ECMA-262 标准后来也被另一个国际标准化组织 ISO(International Organization for Standardization)批准,标准号是 ISO-16262。
- 1998 年 6 月,ECMAScript 2.0 版发布。
- 1999 年 12 月,ECMAScript 3.0 版发布,成为 JavaScript 的通行标准,得到了广泛支持。
- 2007 年 10 月,ECMAScript 4.0 版草案发布,但该版本过于激进,分歧很大。
- 2008 年,Google 公司为 Chrome 浏览器而开发的 V8 编译器诞生。
- 2009 年,Node.js 诞生。Node.js 的出现促进了前端工程化的快速发展,前端由石器时代快速进入了工业时代。
- 2009 年 12 月,ECMAScript 5.0 版正式发布。截止 2012 年底,已得到绝大部分浏览器支持。
- 2010 年,NPM、BackboneJS 和 RequireJS 的出现,标志着 JavaScript 进入模块化开发时代。
- 2013 年 5 月,Facebook 发布 UI 框架库 React,引入了新的 JSX 语法,使得 UI 层可以用组件开发。
- 2015 年 6 月,ECMAScript 6.0 版正式发布,并更名为: ECMAScript 2015 标准。
- 2016 年 6 月,ECMAScript 2016 标准发布。
- 2017 年 6 月,ECMAScript 2017 标准发布,正式引入了 async 函数,使得异步操作的写法出现了根本的变化。
ECMAScript 标准目前保持每年一次发布的速度更新,相应的,部分浏览器对标准的支持会显得有些滞后。
于是,基于对高版本语法转译为低版本语法的各种工具被开发了出来。
下一步,我们来了解下 JavaScript 引擎。
JavaScript 引擎
JavaScript 引擎是一个专门处理 JavaScript 脚本的虚拟机,负责解析 Javascript 语言。
对于浏览器而言,其内核包括:渲染引擎(layout engineer 或者 Rendering Engine)、JavaScript 引擎等。 渲染引擎负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入 CSS 等),以及计算网页的显示方式,然后会输出至显示器或打印机。 浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。
下面是一些 JavaScript 引擎:
- SpiderMonkey,第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
- V8,开放源代码,由 Google 开发,是 Google Chrome 的一部分。
- JavaScriptCore,开放源代码,用于 Safari。
- Chakra (JScript 引擎),用于 Internet Explorer。
- Chakra (JavaScript 引擎),用于 Microsoft Edge。
Babel
在了解了 JavaScript 及其引擎的各项背景后,我们来了解下 Babel。
Babel 是 JavaScript 编译器(来自官网描述)。它将高版本 ECMAScript 语法编译为浏览器都支持的 ES5 语法。
开发者编写的 JavaScript 代码,与浏览器等容器内运行的 JavaScript 通常是不同的,比如为了兼容低版本浏览器,需要将编写时代码转译为运行时代码。 举例:
// 这种语法,在 IE7 等低版本浏览器中是无法识别的,会报语法错误
const fn = (a, b) => a + b;
// 经过 Babel 及其插件编译为 ES5 后,IE7 等浏览器可以识别下面的代码
var fn = function(a, b) {
return a + b;
};Babel 发展史
- 2014 年,Facebook 的澳大利亚的工程师 Sebastian McKenzie 发布了 6to5 这个库,用于将 ES6 转为 ES5,它使用的 AST 转换引擎 fork 自 acorn。
- 2015 年 2 月 15 日,6to5 和 Esnext 的团队决定一起开发 6to5,并改名为 Babel,解析引擎改为 Babylon。后来,Babylon 移入到 @babel/parser。
- 2015-03-31,Babel 5.0 发布。
- 2015-10-30,Babel 6.0 发布。
- Babel 自 6.0 起,就不再对代码进行修改。从这个版本开始,Babel 主要负责 Parse 和 Generate 流程,修改代码的 transform 过程全都交给插件去做。也就是说,Babel 只是一个语法解析器。
- 2018-08-27,Babel 7.0 发布。
Babel 编译原理
Babel 本质上就是一个编译器,将一份代码编译为另一份代码。
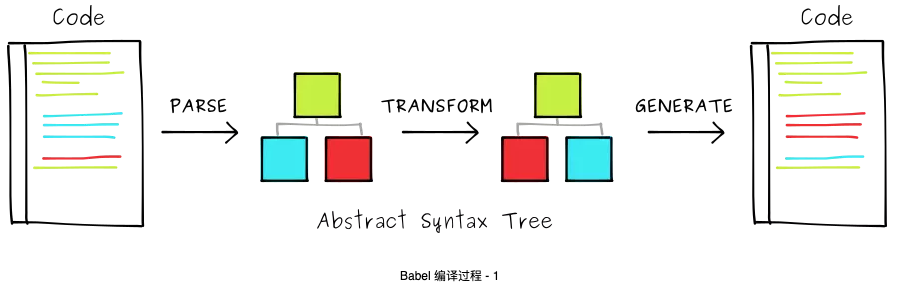
Babel 的编译流程和大部分编译器的编译流程是相似的,包括三个过程:
- 第一阶段:解析( Parsing )
解析 是将最初原始的代码转换为一种更加抽象的表示( AST )。
它包括:词法解析( Lexical Analysis )和语法解析( Syntactic Analysis )。
- 第二阶段:转换( Transormation )
转换阶段会对 AST 进行遍历,在这个过程中对节点进行增删改查。
- 第三阶段:重新生成代码( Code Generation )
编译器有很多种,我们先不考虑其他类型的编译器,先详细了解下 Babel 的整个编译过程。
编译过程如下图:
Babel 在编译过程用到了一些工具集,如下图:
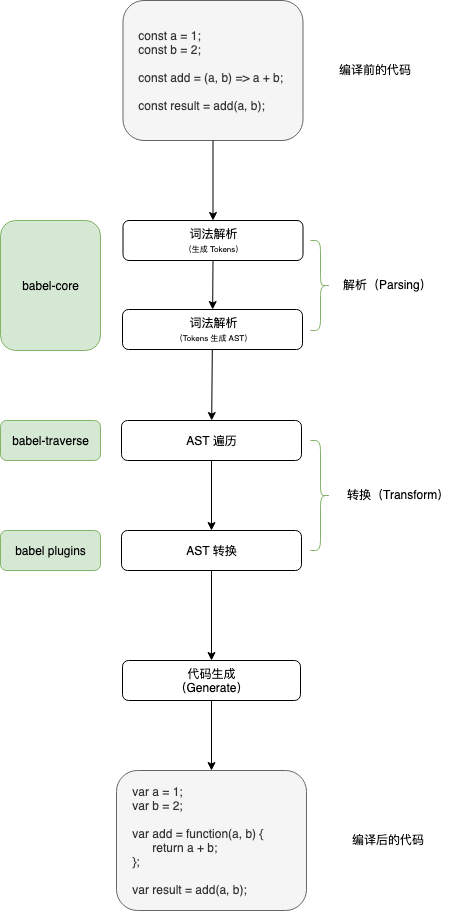
本章,我们从最简单的案例入手理解编译原理,不去深究 Babel 各个模块的源码。
解析
解析 是将最初原始的代码转换为一种更加抽象的表示( AST )。
包括:词法解析( Lexical Analysis )和语法解析( Syntactic Analysis )。
- 词法解析( Lexical Analysis )
词法解析器( Tokenizer ) 在这个阶段将字符串形式的代码转换为 Tokens (令牌),这个过程由词法解析器( Tokenizer 或 Lexer )完成。
令牌( Tokens )是扁平化的语法片段数组,每个数组项包含了:代码片段( value )、代码位置( start / end )、类型( type ) 等信息,这些信息有助于后续的语法分析。
如 n*n 经过词法解析后,转换成的令牌如下:
// n*n
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
...
]每一个 type 有一组属性来描述该令牌:
{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
}
}词法解析器( Tokenizer )本质上就是一个字符串处理方法,入参是字符串,返回结果是数组。
function Tokenizer() {
const tokens = [];
// 字符串解析,并将结果
// processing
// 返回 Token 数组
return tokens;
}- 语法解析( Syntactic Analysis )
语法解析器( Parser ) 会把 Tokens 转换为抽象语法树( Abstract Syntax Tree, AST )。
AST 就是 JavaScript 中的一个 Object Tree,用于表示代码的语法结构。
举个例子:
const a = 1;
const b = 2;
console.log(a + b);会被解析为:

其中,Program、VariableDeclarator、CallExpression 等表示节点类型,每个节点都是一个语法单元。
节点类型的属性描述了节点的详细信息。
JavaScript 中的节点类型非常多,再加上 JSX、Flow 等,我们不需要记忆它们,在需要的时候,ASTExplorer( https://astexplorer.net/ )可以帮助我们快速查看代码的 AST。
很显然,语法解析器接收 Token 数组,转为 AST,本质上是一个转换方法:
function parser(tokens) {
const ast = {
type: 'Program',
body: []
};
// tokens to ast
// processing
return ast;
}转换( Transformation )
这个过程 Babel 会对 AST 进行遍历,并且进行增删改查等转换动作。
Babel 所有插件都是在这个阶段工作, 比如语法转换、代码压缩等。
由于 AST 有众多类型的节点,在遍历 AST 过程中,需要用到 深度遍历 和 Visitor。
深度遍历,就是递归遍历 AST 对象;
Visitor,也就是访问者模式,它是一个对象,其 key 即为各个节点类型,值为各个处理方法。
转换过程如下:
// 转换器定义
function traverse(ast, visitor) {
// 递归遍历
// dfs(ast, visitor)
}
// 转换器执行
traverse(ast, {
Program(node, parent) {
// ...
},
CallExpression(node, parent) {
// ...
},
NumberLiteral(node, parent) {
// ...
}
});重新生成代码( Code Generation )
把 AST 转换回字符串形式的 Javascript,同时这个阶段还会生成 Source Map。
转换器接收一个 AST,并将其转为代码字符串。本质上是对象转字符串的方法。
function transformer(ast) {
let code = '';
// 遍历 AST,拼接 code 字符串
return code;
}