
浏览器工作原理
浏览器结构
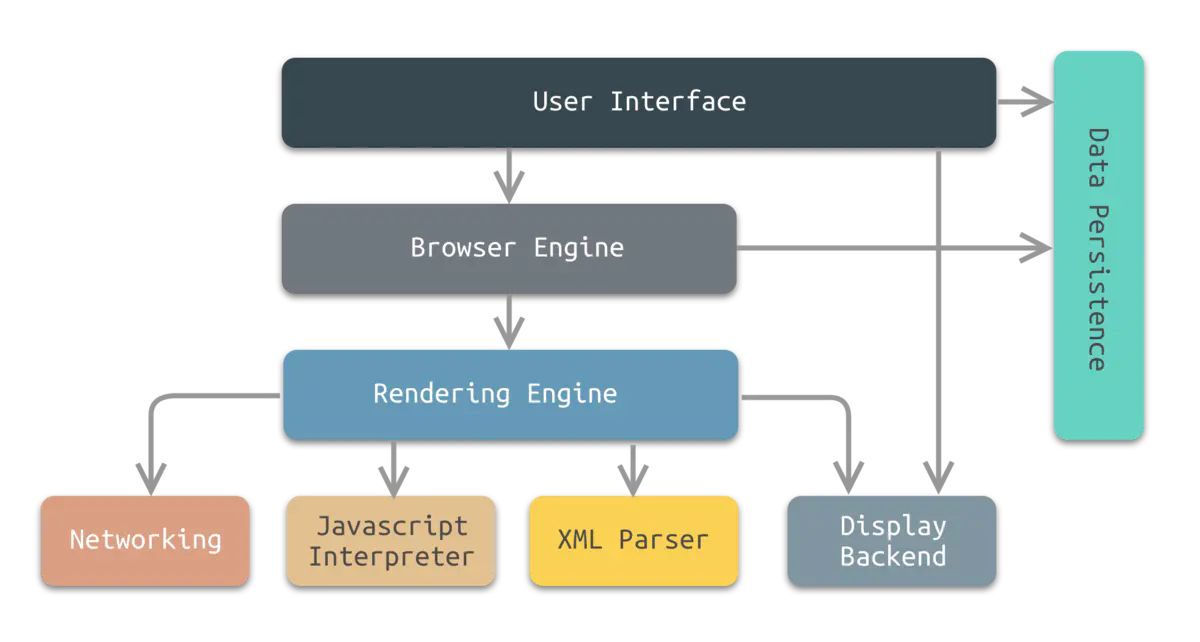
- 用户界面(User Interface):包括地址栏、后退/前进按钮、书签目录等,也就是看到的除了显示所请求页面的主窗口之外的其他部分
- 浏览器引擎(Browser Engine):用来查询及操作渲染引擎的接口,浏览器引擎可以加载一个给定的URI,并支持诸如:前进/后退/重新加载等浏览操作。浏览器引擎提供查看浏览会话的各个方面的挂钩,例如:当前页面加载进度、JavaScript alert。浏览器引擎还允许查询/修改渲染引擎设置。
- 渲染引擎 (Rendering Engine):渲染引擎能够显示HTML和XML文档,可选择CSS样式,以及嵌入式内容(如图片)。渲染引擎能够准确计算页面布局,可使用“回流”算法逐步调整页面元素的位置。渲染引擎内部包含HTML解析器。
- 网络(Networking):网络系统实现HTTP和FTP等文件传输协议。网络系统可以在不同的字符集之间进行转换,为文件解析MIME媒体类型。网络系统可以实现最近检索资源的缓存功能。
- XML解析器(XML Parser):XML解析器可以将XML文档解析成文档对象模型(Document Object Model,DOM)树。XML解析器是浏览器架构中复用最多的子系统之一,几乎所有的浏览器实现都利用现有的XML解析器,而不是从头开始创建自己的XML解析器。
- JS解释器(JavaScript Interpreter):JavaScript解释器能够解释并执行嵌入在网页中的JavaScript(又称ECMAScript)代码。
- 显示后端 (Display Backend):用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
- 数据持久层 (Data Persistence):数据持久层将与浏览会话相关联的各种数据存储在硬盘上。这些数据可能是诸如:书签、工具栏设置等这样的高级数据,也可能是诸如:Cookie,安全证书、缓存等这样的低级数据。
具体可以查看 http://taligarsiel.com/Projects/howbrowserswork1.htm#Thebrowserhighlevelstructure 。
浏览器架构
TIP
首先认识到一个问题:构建一个永不崩溃或挂起的渲染引擎几乎是不可能的。构建一个完全安全的渲染引擎也几乎是不可能的。出自于 https://www.chromium.org/developers/design-documents/multi-process-architecture/
单进程浏览器时代
在2007年之前,市面上的浏览器都是单进程的,即浏览器的所有功能模块都运行在同一个进程中,这些模块包含网络、插件、JavaScript运行环境、渲染引擎和页面等。架构图如下:
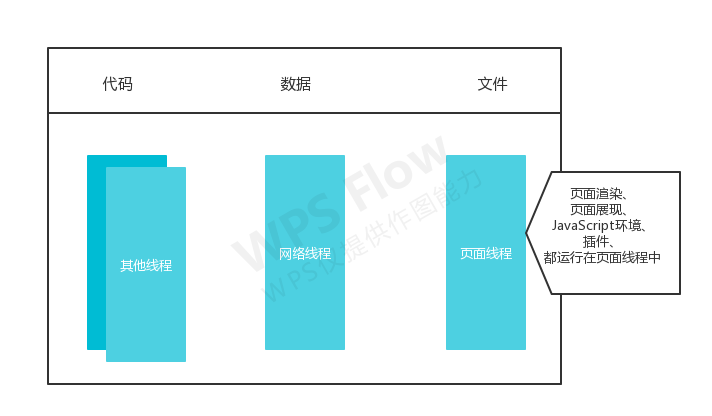
那么如此多个模块都运行在同一个进程中,是导致浏览器不稳定、不流畅和不安全的一个主要因素。
不稳定 早期浏览器需要借助于插件来实现诸如Web视频、Web游戏等各种强⼤的功能,但是插件是最容易出问题的模块,并且还运⾏在浏览器进程之中,所以⼀个插件的意外崩溃会引起整个浏览器的崩溃。 除了插件之外,渲染引擎模块也是不稳定的,通常⼀些复杂的JavaScript代码就有可能引起渲染引擎模块的崩溃。和插件⼀样,渲染引擎的崩溃也会导致整个浏览器的崩溃。
不流畅 从上⾯的“单进程浏览器架构⽰意图”可以看出,所有⻚⾯的渲染模块、JavaScript执⾏环境以及插件都是 运⾏在同⼀个线程中的,这就意味着同⼀时刻只能有⼀个模块可以执⾏。
⽐如,下⾯这个⽆限循环的脚本:
function freeze() {
while (1) {
console.log("freeze");
}
}
freeze();因为这个脚本是⽆限循环的,所以当其执⾏时,它会独占整个线程,这样导致其他运⾏在该线程中的模块就没有机会被执⾏。因为浏览器中所有的⻚⾯都运⾏在该线程中,所以这些⻚⾯都没有机会去执⾏任务,这样就会导致整个浏览器失去响应,变卡顿。
除了上述脚本脚或者插件插会让单进程浏览器变卡顿外,⻚⾯的内存泄漏⻚也是单进程变慢的⼀个重要原因。通常浏览器的内核都是⾮常复杂的,运⾏⼀个复杂点的⻚⾯再关闭⻚⾯,会存在内存不能完全回收的情况,这样导致的问题是使⽤时间越⻓,内存占⽤越⾼,浏览器会变得越慢。
- 不安全 插件可以使⽤C/C++等代码编写,通过插件可以获取到操作系统的任意资源,当你在⻚⾯运⾏⼀个插件时也就意味着这个插件能完全操作你的电脑。如果是个恶意插件,那么它就可以释放病毒、窃取你的账号密码,引发安全性问题。 ⾄于⻚⾯脚本,它可以通过浏览器的漏洞来获取系统权限,这些脚本获取系统权限之后也可以对你的电脑做⼀些恶意的事情,同样也会引发安全问题。
那么为了解决这些问题,我们就进入了多进程浏览器时代了。
多进程浏览器时代
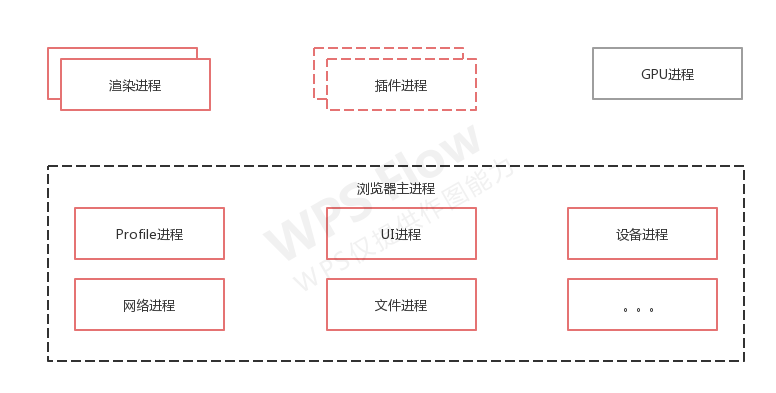
最新的Chrome浏览器包括:1个浏览器(Browser)主进程、1个 GPU 进程、1个⽹络 (NetWork)进程、多个渲染进程和多个插件进程。架构图如下:
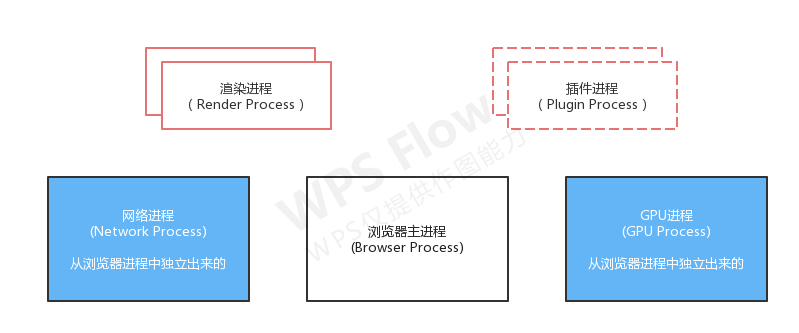
各进程的功能如下:
- 浏览器进程:主要负责界⾯显⽰、⽤⼾交互、⼦进程管理,同时提供存储等功能。
- 渲染进程:核⼼任务是将 HTML、CSS 和 JavaScript 转换为⽤⼾可以与之交互的⽹⻚,排版引擎Blink和 JavaScript引擎V8都是运⾏在该进程中,默认情况下,Chrome会为每个Tab标签创建⼀个渲染进程。出 于安全考虑,渲染进程都是运⾏在沙箱模式下。
- GPU进程:其实,Chrome刚开始发布的时候是没有GPU进程的。⽽GPU的使⽤初衷是为了实现3D CSS的 效果,只是随后⽹⻚、Chrome的UI界⾯都选择采⽤GPU来绘制,这使得GPU成为浏览器普遍的需求。最 后,Chrome在其多进程架构上也引⼊了GPU进程。
- 网络进程:主要负责⻚⾯的⽹络资源加载,之前是作为⼀个模块运⾏在浏览器进程⾥⾯的,直⾄最近才独⽴出来,成为⼀个单独的进程。
- 插件进程:主要是负责插件的运⾏,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃 不会对浏览器和⻚⾯造成影响。
虽然多进程模型提升了浏览器的稳定性、流畅性和安全性,但同样不可避免地带来了⼀些问题。
- 更高的资源占用:因为每个进程都会包含公共基础结构的副本(如JavaScript运⾏环境),这就意味着浏览器会消耗更多的内存资源。
- 更复杂的体系结构:浏览器各模块之间耦合性⾼、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
对于上⾯这两个问题,Chrome团队⼀直在寻求⼀种弹性⽅案,既可以解决资源占⽤⾼的问题,也可以解决 复杂的体系架构的问题。
未来面向服务的架构
为了解决这些问题,在2016年,Chrome官⽅团队使⽤“⾯向服务的架构 ⾯ ”(Services Oriented Architecture,简称SOA S )的思想设计了新的Chrome架构。也就是说 Chrome 整体架构会朝向现代操作系 统所采⽤的“⾯向服务的架构” ⽅向发展,原来的各种模块会被重构成独⽴的服务(Service),每个服务 (Service)都可以在独⽴的进程中运⾏,访问服务(Service)必须使⽤定义好的接⼝,通过IPC来通信, 从⽽构建⼀个更内聚、松耦合、易于维护和扩展的系统 构 ,更好实现 Chrome 简单、稳定、⾼速、安全的⽬ 标。如果你对⾯向服务的架构感兴趣,你可以去⽹上搜索下资料,这⾥就不过多介绍了。
Chrome最终要把UI、数据库、⽂件、设备、⽹络等模块重构为基础服务,类似操作系统底层服务,下⾯是 Chrome“⾯向服务的架构”的进程模型图:
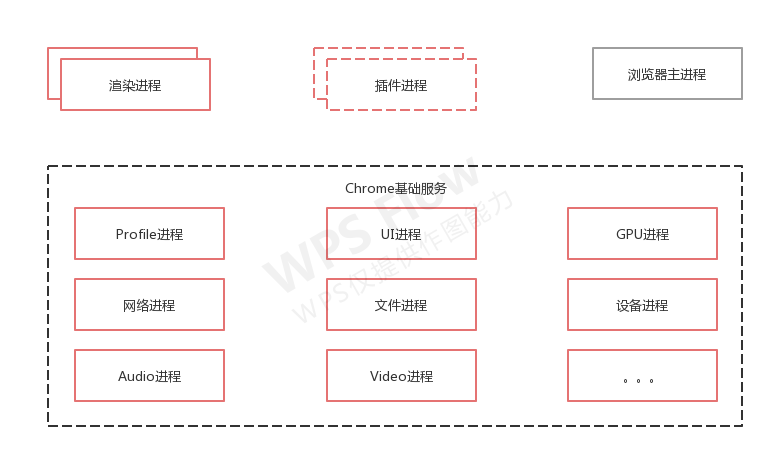
⽬前Chrome正处在⽼的架构向服务化架构过渡阶段,这将是⼀个漫⻓的迭代过程。
Chrome正在逐步构建Chrome基础服务(Chrome Foundation Service),如果你认为Chrome是“便携式 操作系统”,那么Chrome基础服务便可以被视为该操作系统的“基础”系统服务层。
同时Chrome还提供灵活的弹性架构,在强⼤性能设备上会以多进程的⽅式运⾏基础服务,但是如果在资源 受限的设备上(如下图),Chrome会将很多服务整合到⼀个进程中,从⽽节省内存占⽤。
 在资源不⾜的设备上,将服务合并到浏览器进程中
在资源不⾜的设备上,将服务合并到浏览器进程中
从输入 URL 到页面加载完成的过程
在浏览器⾥,从输⼊URL到⻚⾯展⽰,这中间发⽣了什么,往往我们做前端界面的开发很少关注这些内容,但是理解整个流程之后能让我们对浏览器有更深的理解。
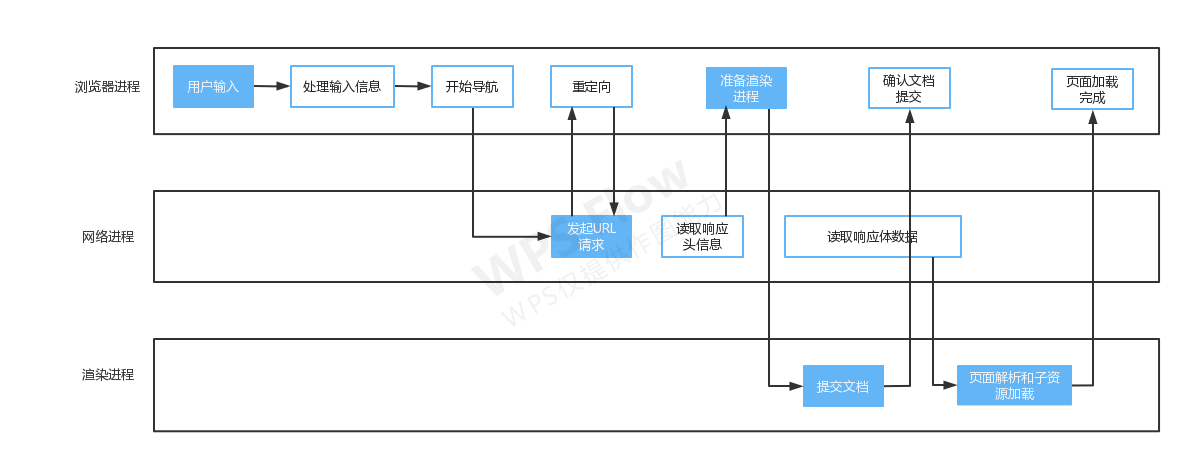
第一步:用户输入,当我们在地址栏输入一个查询关键词时,地址栏会判断当前用户输入的是搜索内容还是URL,如果是搜索内容的话,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键词的URL。比如当我们在chrome浏览器地址栏输入快手小程序,他会默认用google合成新的URL来访问。如果输入的内容符合URL规则的话比如baidu.com,他会根据规则,把这段内容加上协议,合成完成的URL。
第二步:发起URL请求,URL请求部分也就是页面资源请求过程,浏览器进程会通过进程间通信(IPC)把URL请求发送到网络进程。网络进程首先会查找本地缓存是否缓存了该资源,如果有缓存则直接返回到浏览器进程,如果没有缓存,则会发起网络请求流程。网络请求首先会进行DNS解析,根据域名获取对应的服务器地址,如果网络协议是HTTPS,那么还需要进行TLS连接。接下来利用IP地址和服务器建立TCP连接,连接建立之后,浏览器端会构建请求头、请求行等信息,并把和该域名相关的cookie等数据附加到请求头中,然后向服务器发送构建的请求信息。服务器收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程,等网络进程接受了响应行和响应头之后,就开始解析内容了。
第三步:准备渲染进程,默认情况下,Chrome会为每一个页面分配一个渲染进程,也就是每次打开一个window都会创建一个渲染进程,但是有一种情况是如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。
第四步:提交文档,此处的文档指的是URL请求的响应体数据,提交文档的消息是由浏览器进程发出的,渲染进程收到提交文档消息之后,会与网络进程建立通道,等文档传输完成之后,渲染进程会返回确认提交的消息给浏览器进程,浏览器进程收到确认提交的消息后,会更新浏览器的界面状态,包括安全状态、地址栏URL、前进后退的历史状态,并更新Web页面。
第五步:渲染阶段,一旦文档被提交,渲染进程便开始页面解析和子资源加载。首先会将HTML经由HTML解析器解析,最终输出Dom树。渲染引擎会将CSS文本转换为浏览器可以理解的结构–styleSheets,并转换样式表中的属性值,让其标准化,然后就计算Dom树中每个节点的样式属性。创建布局树,并计算元素的布局信息,对布局树分层,并生成分层树。为每个图层生成绘制列表,并将其提交到合成线程,合成线程将图层分为图块,并在光栅化线程池中将图块转换成位图,合成线程发送绘制图块命令DrawQuad给浏览器进程,浏览器进程根据DrawQuad消息生成页面,并显示到显示器上。