
AST实现和编译原理
AST 技术是现代化前端基建和工程化建设的基石:Babel、Webpack、ESLint、代码压缩工具等耳熟能详的工程化基建工具或流程,都离不开 AST 技术;Vue、React 等经典前端框架,也离不开基于 AST 技术的编译。
目前社区上不乏 Babel 插件、Webpack 插件等知识的讲解,但是涉及 AST 的部分,往往都是使用现成工具转载模版代码。
AST 基础知识
我们先对 AST 下一个定义,AST 是 Abstract Syntax Tree 的缩写,表示抽象语法树:
在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax Tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似 if-condition-then 这样的条件跳转语句,可以使用带有三个分支的节点来表示。
AST 的应用场景经常出现在源代码的编译过程中:一般语法分析器创建出 AST,然后 AST 在语义分析阶段添加一些信息,甚至修改 AST 内容,最终产出编译后代码。
AST 初体验
了解了 AST 基本概念,我们对 AST 进行一个“感官认知”。这里提供给你一个平台:AST explorer,在这个平台中,可以实时看到 JavaScript 代码转换为 AST 之后的产出结果。如下图所示:
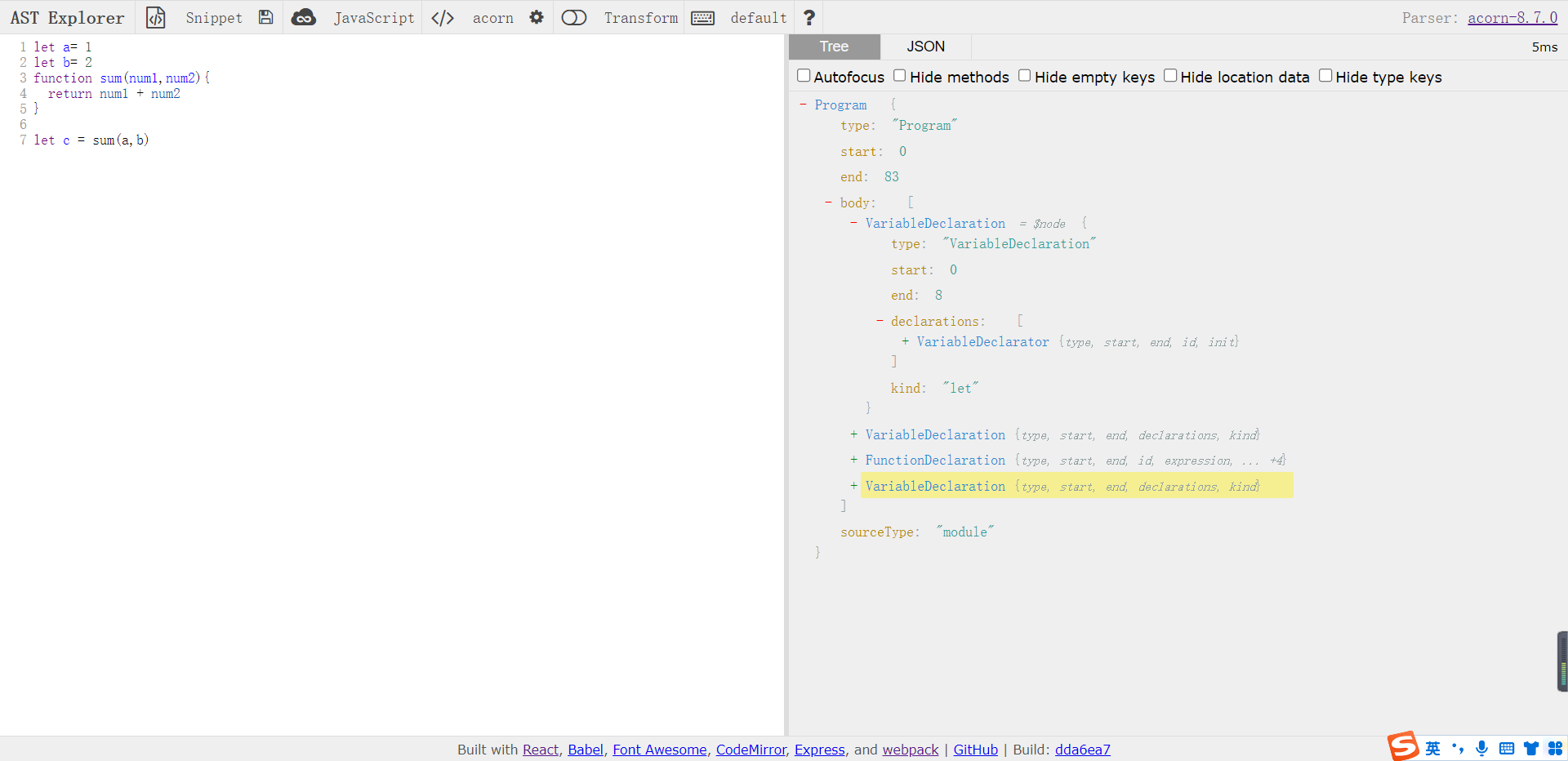
可以看到,经过 AST 转换,我们的 JavaScript 代码(左侧)变成了一种 ESTree 规范的数据结构(右侧),这种数据结构就是 AST。
这个平台实际使用了 acorn 作为 AST 解析器。
acorn 解析
实际上,社区上多项著名项目都依赖的 acorn 的能力(比如 ESLint、Babel、Vue.js 等),acorn 的介绍为:
A tiny, fast JavaScript parser, written completely in JavaScript.
由此可知,acorn 是一个完全使用 JavaScript 实现的、小型且快速的 JavaScript 解析器。基本用法非常简单,代码如下:
let acorn = require('acorn')
let code = 1 + 2
console.log(acorn.parse(code))对所有语法解析器来说,实现流程上很简单,如下图所示: 
源代码经过词法分析,即分词得到 Token 序列,对 Token 序列进行语法分析,得到最终 AST 结果。但 acorn 稍有不同的是:acorn 将词法分析和语法分析交替进行,只需要扫描一遍代码即可得到最终 AST 结果。
acorn 的 Parser 类源码形如:
export class Parser {
constructor(options, input, startPos) {
//...
}
parse() {
// ...
}
// 判断所处 context
get inFunction() { return (this.currentVarScope().flags & SCOPE_FUNCTION) > 0 }
get inGenerator() { return (this.currentVarScope().flags & SCOPE_GENERATOR) > 0 }
get inAsync() { return (this.currentVarScope().flags & SCOPE_ASYNC) > 0 }
get allowSuper() { return (this.currentThisScope().flags & SCOPE_SUPER) > 0 }
get allowDirectSuper() { return (this.currentThisScope().flags & SCOPE_DIRECT_SUPER) > 0 }
get treatFunctionsAsVar() { return this.treatFunctionsAsVarInScope(this.currentScope()) }
get inNonArrowFunction() { return (this.currentThisScope().flags & SCOPE_FUNCTION) > 0 }
static extend(...plugins) {
// ...
}
// 解析入口
static parse(input, options) {
return new this(options, input).parse()
}
static parseExpressionAt(input, pos, options) {
let parser = new this(options, input, pos)
parser.nextToken()
return parser.parseExpression()
}
// 分词入口
static tokenizer(input, options) {
return new this(options, input)
}
}我们稍做解释:
- type 表示当前 Token 类型;
- pos 表示当前 Token 所在源代码中的位置;
- startNode 方法返回当前 AST 节点;
- nextToken 方法从源代码中读取下一个 Token;
- parseTopLevel 方法实现递归向下组装 AST 树。
这是 acorn 实现解析 AST 的入口骨架,实际的分词环节主要解决以下问题。
- 明确需要分析哪些 Token 类型。
- 关键字:import,function,return 等
- 变量名称
- 运算符号
- 结束符号
- 状态机:简单来讲就是消费每一个源代码中的字符,对字符意义进行状态机判断。以“我们对于/的处理”为例,对于3/10的源代码,/就表示一个运算符号;对于var re = /ab+c/源代码来说,/就表示正则运算的起始字符了。
在分词过程中,实现者往往使用一个 Context 来表达一个上下文,实际上Context 是一个栈数据结果
acorn 在语法解析阶段主要完成 AST 的封装以及错误抛出。在这个过程中,需要你了解,一段源代码可以用:
- Program——整个程序
- Statement——语句
- Expression——表达式
来描述。
当然,Program 包含了多段 Statement,Statement 又由多个 Expression 或者 Statement 组成。这三种大元素,就构成了遵循 ESTree 规范的 AST。最终的 AST 产出,也是这三种元素的数据结构拼合。
实现一个简易 Tree Shaking 脚本
目标如下,实现一个 Node.js 脚本 treeShaking.js,执行命令:
node treeShaking test.js可以将test.js中的 dead code 消除。我们使用test.js测试代码如下:
function add(a, b) {
return a + b
}
function multiple(a, b) {
return a * b
}
var firstOp = 9
var secondOp = 10
add(firstOp, secondOp)理论上讲,上述代码中的multiple方法可以被“摇掉”。
我们进入实现环节,首先请看下图,了解整体架构流程: 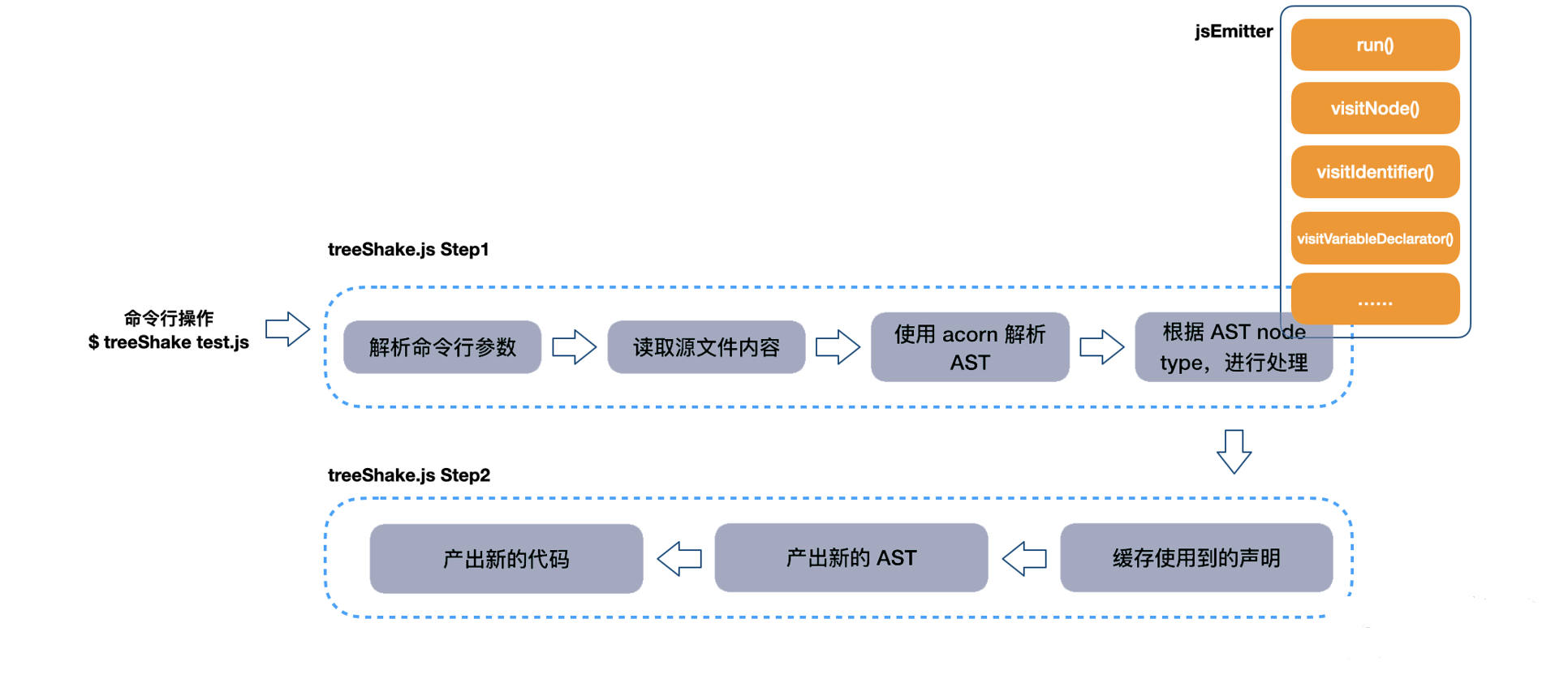
设计 JSEmitter 类,用于根据 AST 产出 JavaScript 代码(js-emitter.js 文件内容):
class JSEmitter {
// 访问变量声明,以下都是工具方法
visitVariableDeclaration(node) {
let str = ''
str += node.kind + ' '
str += this.visitNodes(node.declarations)
return str + '\n'
}
visitVariableDeclarator(node, kind) {
let str = ''
str += kind ? kind + ' ' : str
str += this.visitNode(node.id)
str += '='
str += this.visitNode(node.init)
return str + ';' + '\n'
}
visitIdentifier(node) {
return node.name
}
visitLiteral(node) {
return node.raw
}
visitBinaryExpression(node) {
let str = ''
str += this.visitNode(node.left)
str += node.operator
str += this.visitNode(node.right)
return str + '\n'
}
visitFunctionDeclaration(node) {
let str = 'function '
str += this.visitNode(node.id)
str += '('
for (let param = 0; param < node.params.length; param++) {
str += this.visitNode(node.params[param])
str += ((node.params[param] == undefined) ? '' : ',')
}
str = str.slice(0, str.length - 1)
str += '){'
str += this.visitNode(node.body)
str += '}'
return str + '\n'
}
visitBlockStatement(node) {
let str = ''
str += this.visitNodes(node.body)
return str
}
visitCallExpression(node) {
let str = ''
const callee = this.visitIdentifier(node.callee)
str += callee + '('
for (const arg of node.arguments) {
str += this.visitNode(arg) + ','
}
str = str.slice(0, str.length - 1)
str += ');'
return str + '\n'
}
visitReturnStatement(node) {
let str = 'return ';
str += this.visitNode(node.argument)
return str + '\n'
}
visitExpressionStatement(node) {
return this.visitNode(node.expression)
}
visitNodes(nodes) {
let str = ''
for (const node of nodes) {
str += this.visitNode(node)
}
return str
}
// 根据类型,执行相关处理函数
visitNode(node) {
let str = ''
switch (node.type) {
case 'VariableDeclaration':
str += this.visitVariableDeclaration(node)
break;
case 'VariableDeclarator':
str += this.visitVariableDeclarator(node)
break;
case 'Literal':
str += this.visitLiteral(node)
break;
case 'Identifier':
str += this.visitIdentifier(node)
break;
case 'BinaryExpression':
str += this.visitBinaryExpression(node)
break;
case 'FunctionDeclaration':
str += this.visitFunctionDeclaration(node)
break;
case 'BlockStatement':
str += this.visitBlockStatement(node)
break;
case "CallExpression":
str += this.visitCallExpression(node)
break;
case "ReturnStatement":
str += this.visitReturnStatement(node)
break;
case "ExpressionStatement":
str += this.visitExpressionStatement(node)
break;
}
return str
}
// 入口
run(body) {
let str = ''
str += this.visitNodes(body)
return str
}
}
module.exports = JSEmitter我们来具体分析一下,JSEmitter 类中创建了很多 visitXXX 方法,他们最终都会产出 JavaScript 代码。我们继续结合treeShaking.js的实现来理解:
const acorn = require("acorn")
const l = console.log
const JSEmitter = require('./js-emitter')
const fs = require('fs')
// 获取命令行参数
const args = process.argv[2]
const buffer = fs.readFileSync(args).toString()
const body = acorn.parse(buffer).body
const jsEmitter = new JSEmitter()
let decls = new Map()
let calledDecls = []
let code = []
// 遍历处理
body.forEach(function(node) {
if (node.type == "FunctionDeclaration") {
const code = jsEmitter.run([node])
decls.set(jsEmitter.visitNode(node.id), code)
return;
}
if (node.type == "ExpressionStatement") {
if (node.expression.type == "CallExpression") {
const callNode = node.expression
calledDecls.push(jsEmitter.visitIdentifier(callNode.callee))
const args = callNode.arguments
for (const arg of args) {
if (arg.type == "Identifier") {
calledDecls.push(jsEmitter.visitNode(arg))
}
}
}
}
if (node.type == "VariableDeclaration") {
const kind = node.kind
for (const decl of node.declarations) {
decls.set(jsEmitter.visitNode(decl.id), jsEmitter.visitVariableDeclarator(decl, kind))
}
return
}
if (node.type == "Identifier") {
calledDecls.push(node.name)
}
code.push(jsEmitter.run([node]))
});
// 生成 code
code = calledDecls.map(c => {
return decls.get(c)
}).concat([code]).join('')
fs.writeFileSync('test.shaked.js', code)对于上面代码分析,首先我们通过process.argv获取到目标文件,对于目标文件通过fs.readFileSync()方法读出字符串形式的内容buffer,对于这个buffer变量,我们使用acorn.parse进行解析,并对产出内容进行遍历。
在遍历过程中,对于不同的节点类型,调用 JS Emitter 实例不同的处理方法。在整个过程中,我们维护了:
- decls——Map 类型
- calledDecls——数组类型
- code——数组类型
三个关键变量。decls存储所有的函数或变量声明类型节点,calledDecls则存储了代码中真正使用到的数或变量声明,code存储了其他所有没有被节点类型匹配的 AST 部分。
下面我们来分析具体的遍历过程。
- 在遍历过程中,我们对所有函数和变量的声明,都维护到decls中。
- 接着,我们对所有的 CallExpression 和 IDentifier 进行检测。因为 CallExpression 代表了一次函数调用,因此在该 if 条件分支内,将相关函数节点调用情况推入到calledDecls数组中,同时我们对于该函数的参数变量也推入到calledDecls数组。因为 IDentifier 代表了一个变量的取值,我们也推入到calledDecls数组。
经过整个 AST 遍历,我们就可以只遍历calledDecls数组,并从decls变量中获取使用到的变量和函数声明,最终使用concat方法合并带入code变量中,使用join方法转化为字符串类型。
至此,我们的简易版 Tree Shaking 实现就完成了。