
数组原理
JavaScript 数组的 API 经常会被 JS 开发者频繁使用,在整个 JavaScript 的学习过程中尤为重要。
数组作为一个最基础的一维数据结构,在各种编程语言中都充当着至关重要的角色,你很难想象没有数组的编程语言会是什么模样。特别是 JavaScript,它天生的灵活性,又进一步发挥了数组的特长,丰富了数组的使用场景。可以毫不夸张地说,不深入地了解数组,就不足以写好 JavaScript。
随着前端框架的不断演进,React 和 Vue 等 MVVM 框架的流行,数据更新的同时视图也会随之更新。在通过前端框架实现大量的业务代码中,开发者都会用数组来进行数据的存储和各种“增删改查”等操作,从而实现对应前端视图层的更新。可见熟练掌握数组各种方法,并深入了解数组是很有必要的。
数组概念的探究
截至 ES7 规范,数组共包含 33 个标准的 API 方法和一个非标准的 API 方法,使用场景和使用方案纷繁复杂,其中还有不少坑。为了方便你可以循序渐进地学习这部分的内容,下面我将从数组的概念开始讲起。
由于数组的 API 较多,很多相近的名字也容易导致混淆,所以在这里我按照“会改变自身值的”“不会改变自身值的”“遍历方法”这三种类型分开讲解,让你对这些 API 形成更结构化的认识。
Array 的构造器
Array 构造器用于创建一个新的数组。通常,我们推荐使用对象字面量的方式创建一个数组,例如 var a = [] 就是一个比较好的写法。但是,总有对象字面量表述乏力的时候,比如,我想创建一个长度为 6 的空数组,用对象字面量的方式是无法创建的,因此只能写成下述代码这样。
// 使用 Array 构造器,可以自定义长度
var a = Array(6); // [empty × 6]
// 使用对象字面量
var b = [];
b.length = 6; // [undefined × 6]Array 构造器根据参数长度的不同,有如下两种不同的处理方式:
new Array(arg1, arg2,…),参数长度为 0 或长度大于等于 2 时,传入的参数将按照顺序依次成为新数组的第 0 至第 N 项(参数长度为 0 时,返回空数组);new Array(len),当 len 不是数值时,处理同上,返回一个只包含 len 元素一项的数组;当 len 为数值时,len 最大不能超过 32 位无符号整型,即需要小于 2 的 32 次方(len 最大为 Math.pow(2,32)),否则将抛出 RangeError。
以上就是 Array 构造器的基本情况,我们来看下 ES6 新增的几个构造方法。
ES6 新增的构造方法:Array.of 和 Array.from
鉴于数组的常用性,ES6 专门扩展了数组构造器 Array ,新增了 2 个方法:Array.of、Array.from。其中,Array.of 整体用得比较少;而 Array.from 具有灵活性,你在平常开发中应该会经常使用。那么关于两者的使用细节你真的了解吗?下面展开来聊下这两个方法。
Array.of
Array.of 用于将参数依次转化为数组中的一项,然后返回这个新数组,而不管这个参数是数字还是其他。它基本上与 Array 构造器功能一致,唯一的区别就在单个数字参数的处理上。
比如,在下面的这几行代码中,你可以看到区别:当参数为两个时,返回的结果是一致的;当参数是一个时,Array.of 会把参数变成数组里的一项,而构造器则会生成长度和第一个参数相同的空数组。
Array.of(8.0); // [8]
Array(8.0); // [empty × 8]
Array.of(8.0, 5); // [8, 5]
Array(8.0, 5); // [8, 5]
Array.of('8'); // ["8"]
Array('8'); // ["8"]Array.from
Array.from 的设计初衷是快速便捷地基于其他对象创建新数组,准确来说就是从一个类似数组的可迭代对象中创建一个新的数组实例。其实就是,只要一个对象有迭代器,Array.from 就能把它变成一个数组(注意:是返回新的数组,不改变原对象)。
从语法上看,Array.from 拥有 3 个参数:
- 类似数组的对象,必选;
- 加工函数,新生成的数组会经过该函数的加工再返回;
- this 作用域,表示加工函数执行时 this 的值。
这三个参数里面第一个参数是必选的,后两个参数都是可选的。我们通过一段代码来看看它的用法。
var obj = {0: 'a', 1: 'b', 2:'c', length: 3};
Array.from(obj, function(value, index){
console.log(value, index, this, arguments.length);
return value.repeat(3); //必须指定返回值,否则返回 undefined
}, obj); 结果中可以看出 console.log(value, index, this, arguments.length) 对应的四个值,并且看到 return 的 value 重复了三遍,最后返回的数组为 ["aaa","bbb","ccc"]。
结果中可以看出 console.log(value, index, this, arguments.length) 对应的四个值,并且看到 return 的 value 重复了三遍,最后返回的数组为 ["aaa","bbb","ccc"]。
这表明了通过 Array.from 这个方法可以自己定义加工函数的处理方式,从而返回想要得到的值;如果不确定返回值,则会返回 undefined,最终生成的也是一个包含若干个 undefined 元素的空数组。
实际上,如果这里不指定 this 的话,加工函数完全可以是一个箭头函数。上述代码可以简写为如下形式。
Array.from(obj, (value) => value.repeat(3));
// 控制台返回 (3) ["aaa", "bbb", "ccc"]除了上述 obj 对象以外,拥有迭代器的对象还包括 String、Set、Map 等,Array.from 统统可以处理,请看下面的代码。
// String
Array.from('abc'); // ["a", "b", "c"]
// Set
Array.from(new Set(['abc', 'def'])); // ["abc", "def"]
// Map
Array.from(new Map([[1, 'ab'], [2, 'de']]));
// [[1, 'ab'], [2, 'de']]Array 的判断
Array.isArray 用来判断一个变量是否为数组类型,在 ES5 提供该方法之前,我们至少有如下 5 种方式去判断一个变量是否为数组。
var a = [];
// 1.基于instanceof
a instanceof Array;
// 2.基于constructor
a.constructor === Array;
// 3.基于Object.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(a);
// 4.基于getPrototypeOf
Object.getPrototypeOf(a) === Array.prototype;
// 5.基于Object.prototype.toString
Object.prototype.toString.apply(a) === '[object Array]';ES6 之后新增了一个 Array.isArray 方法,能直接判断数据类型是否为数组,但是如果 isArray 不存在,那么 Array.isArray 的 polyfill 通常可以这样写:
if (!Array.isArray){
Array.isArray = function(arg){
return Object.prototype.toString.call(arg) === '[object Array]';
};
}数组的基本概念到这里基本讲得差不多了,下面我们就来看看让人眼花缭乱的 30 多个数组的基本方法。
改变自身的方法
基于 ES6,会改变自身值的方法一共有 9 个,分别为 pop、push、reverse、shift、sort、splice、unshift,以及两个 ES6 新增的方法 copyWithin 和 fill。
// pop方法
var array = ["cat", "dog", "cow", "chicken", "mouse"];
var item = array.pop();
console.log(array); // ["cat", "dog", "cow", "chicken"]
console.log(item); // mouse
// push方法
var array = ["football", "basketball", "badminton"];
var i = array.push("golfball");
console.log(array);
// ["football", "basketball", "badminton", "golfball"]
console.log(i); // 4
// reverse方法
var array = [1,2,3,4,5];
var array2 = array.reverse();
console.log(array); // [5,4,3,2,1]
console.log(array2===array); // true
// shift方法
var array = [1,2,3,4,5];
var item = array.shift();
console.log(array); // [2,3,4,5]
console.log(item); // 1
// unshift方法
var array = ["red", "green", "blue"];
var length = array.unshift("yellow");
console.log(array); // ["yellow", "red", "green", "blue"]
console.log(length); // 4
// sort方法
var array = ["apple","Boy","Cat","dog"];
var array2 = array.sort();
console.log(array); // ["Boy", "Cat", "apple", "dog"]
console.log(array2 == array); // true
// splice方法
var array = ["apple","boy"];
var splices = array.splice(1,1);
console.log(array); // ["apple"]
console.log(splices); // ["boy"]
// copyWithin方法
var array = [1,2,3,4,5];
var array2 = array.copyWithin(0,3);
console.log(array===array2,array2); // true [4, 5, 3, 4, 5]
// fill方法
var array = [1,2,3,4,5];
var array2 = array.fill(10,0,3);
console.log(array===array2,array2);
// true [10, 10, 10, 4, 5], 可见数组区间[0,3]的元素全部替换为10不改变自身的方法
基于 ES7,不会改变自身的方法也有 9 个,分别为 concat、join、slice、toString、toLocaleString、indexOf、lastIndexOf、未形成标准的 toSource,以及 ES7 新增的方法 includes。
// concat方法
var array = [1, 2, 3];
var array2 = array.concat(4,[5,6],[7,8,9]);
console.log(array2); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(array); // [1, 2, 3], 可见原数组并未被修改
// join方法
var array = ['We', 'are', 'Chinese'];
console.log(array.join()); // "We,are,Chinese"
console.log(array.join('+')); // "We+are+Chinese"
// slice方法
var array = ["one", "two", "three","four", "five"];
console.log(array.slice()); // ["one", "two", "three","four", "five"]
console.log(array.slice(2,3)); // ["three"]
// toString方法
var array = ['Jan', 'Feb', 'Mar', 'Apr'];
var str = array.toString();
console.log(str); // Jan,Feb,Mar,Apr
// tolocalString方法
var array= [{name:'zz'}, 123, "abc", new Date()];
var str = array.toLocaleString();
console.log(str); // [object Object],123,abc,2016/1/5 下午1:06:23
// indexOf方法
var array = ['abc', 'def', 'ghi','123'];
console.log(array.indexOf('def')); // 1
// includes方法
var array = [-0, 1, 2];
console.log(array.includes(+0)); // true
console.log(array.includes(1)); // true
var array = [NaN];
console.log(array.includes(NaN)); // true上面我把不会改变数组的几个方法大致做了一个回顾,其中 includes 方法需要注意的是,如果元素中有 0,那么在判断过程中不论是 +0 还是 -0 都会判断为 True,这里的 includes 忽略了 +0 和 -0。
另外还有一个值得强调的是slice 不改变自身,而 splice 会改变自身,你还是需要注意不要记错了。其中,slice 的语法是:arr.slice([start[, end]]),而 splice 的语法是:arr.splice(start,deleteCount[, item1[, item2[, …]]])。我们可以看到从第二个参数开始,二者就已经有区别了,splice 第二个参数是删除的个数,而 slice 的第二个参数是 end 的坐标(可选)。
数组遍历的方法
基于 ES6,不会改变自身的遍历方法一共有 12 个,分别为 forEach、every、some、filter、map、reduce、reduceRight,以及 ES6 新增的方法 entries、find、findIndex、keys、values。
// forEach方法
var array = [1, 3, 5];
var obj = {name:'cc'};
var sReturn = array.forEach(function(value, index, array){
array[index] = value;
console.log(this.name); // cc被打印了三次, this指向obj
},obj);
console.log(array); // [1, 3, 5]
console.log(sReturn); // undefined, 可见返回值为undefined
// every方法
var o = {0:10, 1:8, 2:25, length:3};
var bool = Array.prototype.every.call(o,function(value, index, obj){
return value >= 8;
},o);
console.log(bool); // true
// some方法
var array = [18, 9, 10, 35, 80];
var isExist = array.some(function(value, index, array){
return value > 20;
});
console.log(isExist); // true
// map 方法
var array = [18, 9, 10, 35, 80];
array.map(item => item + 1);
console.log(array); // [19, 10, 11, 36, 81]
// filter 方法
var array = [18, 9, 10, 35, 80];
var array2 = array.filter(function(value, index, array){
return value > 20;
});
console.log(array2); // [35, 80]
// reduce方法
var array = [1, 2, 3, 4];
var s = array.reduce(function(previousValue, value, index, array){
return previousValue * value;
},1);
console.log(s); // 24
// ES6写法更加简洁
array.reduce((p, v) => p * v); // 24
// reduceRight方法 (和reduce的区别就是从后往前累计)
var array = [1, 2, 3, 4];
array.reduceRight((p, v) => p * v); // 24
// entries方法
var array = ["a", "b", "c"];
var iterator = array.entries();
console.log(iterator.next().value); // [0, "a"]
console.log(iterator.next().value); // [1, "b"]
console.log(iterator.next().value); // [2, "c"]
console.log(iterator.next().value); // undefined, 迭代器处于数组末尾时, 再迭代就会返回undefined
// find & findIndex方法
var array = [1, 3, 5, 7, 8, 9, 10];
function f(value, index, array){
return value%2==0; // 返回偶数
}
function f2(value, index, array){
return value > 20; // 返回大于20的数
}
console.log(array.find(f)); // 8
console.log(array.find(f2)); // undefined
console.log(array.findIndex(f)); // 4
console.log(array.findIndex(f2)); // -1
// keys方法
[...Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[...new Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// values方法
var array = ["abc", "xyz"];
var iterator = array.values();
console.log(iterator.next().value);//abc
console.log(iterator.next().value);//xyz其中,要注意有些遍历方法不会返回处理之后的数组,比如 forEach;有些方法会返回处理之后的数组,比如 filter。这个细节你需要牢记,这样才会在面试过程中正确作答。
reduce 方法也需要重点关注,其参数复杂且多,通常一些复杂的逻辑处理,其实使用 reduce 很容易就可以解决。我们重点看一下,reduce 到底能解决什么问题呢?先看下 reduce 的两个参数。
首先是 callback(一个在数组的每一项中调用的函数,接受四个参数):
- previousValue(上一次调用回调函数时的返回值,或者初始值)
- currentValue(当前正在处理的数组元素)
- currentIndex(当前正在处理的数组元素下标)
- array(调用 reduce() 方法的数组)
然后是 initialValue(可选的初始值,作为第一次调用回调函数时传给 previousValue 的值)。
光靠文字描述其实看着会比较懵,我们还是通过一个例子来说明 reduce 的功能到底有多么强大。
/* 题目:数组 arr = [1,2,3,4] 求数组的和:*/
// 第一种方法:
var arr = [1,2,3,4];
var sum = 0;
arr.forEach(function(e){sum += e;}); // sum = 10
// 第二种方法
var arr = [1,2,3,4];
var sum = 0;
arr.map(function(obj){sum += obj});
// 第三种方法
var arr = [1,2,3,4];
arr.reduce(function(pre,cur){return pre + cur});从上面代码可以看出,我们分别用了 forEach 和 map 都能实现数组的求和,其中需要另外新定义一个变量 sum,再进行累加求和,最后再来看 sum 的值,而 reduce 不仅可以少定义一个变量,而且也会直接返回最后累加的结果,是不是问题就可以轻松解决了?
类数组
JS 中一直存在一种类数组的对象,它们不能直接调用数组的方法,但是又和数组比较类似,在某些特定的编程场景中会出现。我们先来看看在 JavaScript 中有哪些情况下的对象是类数组呢?主要有以下几种:
- 函数里面的参数对象 arguments;
- 用 getElementsByTagName/ClassName/Name 获得的 HTMLCollection;
- 用 querySelector 获得的 NodeList。
arguments
先来重点讲讲 arguments 对象,我们在日常开发中经常会遇到各种类数组对象,最常见的便是在函数中使用的 arguments,它的对象只定义在函数体中,包括了函数的参数和其他属性。我们通过一段代码来看下 arguments 的使用方法,如下所示。
function foo(name, age, sex) {
console.log(arguments);
console.log(typeof arguments);
console.log(Object.prototype.toString.call(arguments));
}
foo('jack', '18', 'male');这段代码比较容易,就是直接将这个函数的 arguments 在函数内部打印出来,那么我们看下这个 arguments 打印出来的结果,请看控制台的这张截图。  从结果中可以看到,typeof 这个 arguments 返回的是 object,通过 Object.prototype.toString.call 返回的结果是 '[object arguments]',可以看出来返回的不是 '[object array]',说明 arguments 和数组还是有区别的。
从结果中可以看到,typeof 这个 arguments 返回的是 object,通过 Object.prototype.toString.call 返回的结果是 '[object arguments]',可以看出来返回的不是 '[object array]',说明 arguments 和数组还是有区别的。
HTMLCollection
HTMLCollection 简单来说是 HTML DOM 对象的一个接口,这个接口包含了获取到的 DOM 元素集合,返回的类型是类数组对象,如果用 typeof 来判断的话,它返回的是 'object'。它是及时更新的,当文档中的 DOM 变化时,它也会随之变化。
var elem1, elem2;
// document.forms 是一个 HTMLCollection
elem1 = document.forms[0];
elem2 = document.forms.item(0);
console.log(elem1);
console.log(elem2);
console.log(typeof elem1);
console.log(Object.prototype.toString.call(elem1));NodeList
NodeList 对象是节点的集合,通常是由 querySlector 返回的。NodeList 不是一个数组,也是一种类数组。虽然 NodeList 不是一个数组,但是可以使用 for...of 来迭代。在一些情况下,NodeList 是一个实时集合,也就是说,如果文档中的节点树发生变化,NodeList 也会随之变化。
var list = document.querySelectorAll('input[type=checkbox]');
for (var checkbox of list) {
checkbox.checked = true;
}
console.log(list);
console.log(typeof list);
console.log(Object.prototype.toString.call(list));类数组应用场景
我在这里为你介绍三种场景,这些也是最常见的。
遍历参数操作
我们在函数内部可以直接获取 arguments 这个类数组的值,那么也可以对于参数进行一些操作,比如下面这段代码,我们可以将函数的参数默认进行求和操作。
function add() {
var sum =0,
len = arguments.length;
for(var i = 0; i < len; i++){
sum += arguments[i];
}
return sum;
}
add() // 0
add(1) // 1
add(1,2) // 3
add(1,2,3,4); // 10结合上面这段代码,我们在函数内部可以将参数直接进行累加操作,以达到预期的效果,参数多少也可以不受限制,根据长度直接计算,返回出最后函数的参数的累加结果,其他的操作也都可以仿照这样的方式来做。我们再看下一种场景。
定义链接字符串函数
我们可以通过 arguments 这个例子定义一个函数来连接字符串。这个函数唯一正式声明了的参数是一个字符串,该参数指定一个字符作为衔接点来连接字符串。该函数定义如下。
function myConcat(separa) {
var args = Array.prototype.slice.call(arguments, 1);
return args.join(separa);
}
myConcat(", ", "red", "orange", "blue");
// "red, orange, blue"
myConcat("; ", "elephant", "lion", "snake");
// "elephant; lion; snake"
myConcat(". ", "one", "two", "three", "four", "five");
// "one. two. three. four. five"这段代码说明了,你可以传递任意数量的参数到该函数,并使用每个参数作为列表中的项创建列表进行拼接。从这个例子中也可以看出,我们可以在日常编码中采用这样的代码抽象方式,把需要解决的这一类问题,都抽象成通用的方法,来提升代码的可复用性。
传递参数使用
可以借助 arguments 将参数从一个函数传递到另一个函数,请看下面这个例子。
// 使用 apply 将 foo 的参数传递给 bar
function foo() {
bar.apply(this, arguments);
}
function bar(a, b, c) {
console.log(a, b, c);
}
foo(1, 2, 3) //1 2 3上述代码中,通过在 foo 函数内部调用 apply 方法,用 foo 函数的参数传递给 bar 函数,这样就实现了借用参数的妙用。你可以结合这个例子再思考一下,对于 foo 这样的函数可以灵活传入参数数量,通过这样的代码编写方式是不是也可以实现一些功能的拓展场景呢?
如何将类数组转换成数组
在互联网大厂的面试中,类数组转换成数组这样的题目经常会问,也会问你 arguments 的相关问题
类数组借用数组方法转数组
apply 和 call 方法之前我们有详细讲过,类数组因为不是真正的数组,所以没有数组类型上自带的那些方法,我们就需要利用下面这几个方法去借用数组的方法。比如借用数组的 push 方法,请看下面的一段代码。
var arrayLike = {
0: 'java',
1: 'script',
length: 2
}
Array.prototype.push.call(arrayLike, 'jack', 'lily');
console.log(typeof arrayLike); // 'object'
console.log(arrayLike);
// {0: "java", 1: "script", 2: "jack", 3: "lily", length: 4}从中可以看到,arrayLike 其实是一个对象,模拟数组的一个类数组,从数据类型上说它是一个对象,新增了一个 length 的属性。从代码中还可以看出,用 typeof 来判断输出的是 'object',它自身是不会有数组的 push 方法的,这里我们就用 call 的方法来借用 Array 原型链上的 push 方法,可以实现一个类数组的 push 方法,给 arrayLike 添加新的元素。
从控制台的结果可以看出,数组的 push 方法满足了我们想要实现添加元素的诉求。我们再来看下 arguments 如何转换成数组,请看下面这段代码。
function sum(a, b) {
let args = Array.prototype.slice.call(arguments);
// let args = [].slice.call(arguments); // 这样写也是一样效果
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = Array.prototype.concat.apply([], arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3这段代码中可以看到,还是借用 Array 原型链上的各种方法,来实现 sum 函数的参数相加的效果。一开始都是将 arguments 通过借用数组的方法转换为真正的数组,最后都又通过数组的 reduce 方法实现了参数转化的真数组 args 的相加,最后返回预期的结果。
ES6 的方法转数组
对于类数组转换成数组的方式,我们还可以采用 ES6 新增的 Array.from 方法以及展开运算符的方法。那么还是围绕上面这个 sum 函数来进行改变,我们看下用 Array.from 和展开运算符是怎么实现转换数组的,请看下面一段代码的例子。
function sum(a, b) {
let args = Array.from(arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = [...arguments];
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(...args) {
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3从代码中可以看出,Array.from 和 ES6 的展开运算符,都可以把 arguments 这个类数组转换成数组 args,从而实现调用 reduce 方法对参数进行累加操作。其中第二种和第三种都是用 ES6 的展开运算符,虽然写法不一样,但是基本都可以满足多个参数实现累加的效果。
数组扁平化
扁平化的实现
数组的扁平化其实就是将一个嵌套多层的数组 array(嵌套可以是任何层数)转换为只有一层的数组。举个简单的例子,假设有个名为 flatten 的函数可以做到数组扁平化,效果如下面这段代码所示。
var arr = [1, [2, [3, 4,5]]];
console.log(flatten(arr)); // [1, 2, 3, 4,5]其实就是把多维的数组“拍平”,输出最后的一维数组。那么你知道了效果是什么样的了,下面就尝试着写一个 flatten 函数吧。实现方式有下述几种。
方法一:普通的递归实
普通的递归思路很容易理解,就是通过循环递归的方式,一项一项地去遍历,如果每一项还是一个数组,那么就继续往下遍历,利用递归程序的方法,来实现数组的每一项的连接。我们来看下这个方法是如何实现的,如下所示。
// 方法1
var a = [1, [2, [3, 4, 5]]];
function flatten(arr) {
let result = [];
for(let i = 0; i < arr.length; i++) {
if(Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
flatten(a); // [1, 2, 3, 4,5]从上面这段代码可以看出,最后返回的结果是扁平化的结果,这段代码核心就是循环遍历过程中的递归操作,就是在遍历过程中发现数组元素还是数组的时候进行递归操作,把数组的结果通过数组的 concat 方法拼接到最后要返回的 result 数组上,那么最后输出的结果就是扁平化后的数组。
方法二:利用 reduce 函数迭代
从上面普通的递归函数中可以看出,其实就是对数组的每一项进行处理,那么我们其实也可以用第 7 讲中说的 reduce 来实现数组的拼接,从而简化第一种方法的代码,改造后的代码如下所示。
// 方法2
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.reduce(function(prev, next){
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}
console.log(flatten(arr));// [1, 2, 3, 4,5]这段代码在控制台执行之后,也可以得到想要的结果。这里你可以回忆一下之前说的 reduce 的参数问题,我们可以看到 reduce 的第一个参数用来返回最后累加的结果,思路和第一种递归方法是一样的,但是通过使用 reduce 之后代码变得更简洁了,也同样解决了扁平化的问题。
方法三:扩展运算符实现
这个方法的实现,采用了扩展运算符和 some 的方法,两者共同使用,达到数组扁平化的目的,还是来看一下代码。
// 方法3
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]从执行的结果中可以发现,我们先用数组的 some 方法把数组中仍然是组数的项过滤出来,然后执行 concat 操作,利用 ES6 的展开运算符,将其拼接到原数组中,最后返回原数组,达到了预期的效果。
前三种实现数组扁平化的方式其实是最基本的思路,都是通过最普通递归思路衍生的方法,尤其是前两种实现方法比较类似。值得注意的是 reduce 方法,它可以在很多应用场景中实现,由于 reduce 这个方法提供的几个参数比较灵活,能解决很多问题,所以是值得熟练使用并且精通的。
方法四:split 和 toString 共同处理
我们也可以通过 split 和 toString 两个方法,来共同实现数组扁平化,由于数组会默认带一个 toString 的方法,所以可以把数组直接转换成逗号分隔的字符串,然后再用 split 方法把字符串重新转换为数组,如下面的代码所示。
// 方法4
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.toString().split(',');
}
console.log(flatten(arr)); // [1, 2, 3, 4]通过这两个方法可以将多维数组直接转换成逗号连接的字符串,然后再重新分隔成数组,你可以在控制台执行一下查看结果。
方法五:调用 ES6 中的 flat
我们还可以直接调用 ES6 中的 flat 方法,可以直接实现数组扁平化。先来看下 flat 方法的语法:
arr.flat([depth])其中 depth 是 flat 的参数,depth 是可以传递数组的展开深度(默认不填、数值是 1),即展开一层数组。那么如果多层的该怎么处理呢?参数也可以传进 Infinity,代表不论多少层都要展开。那么我们来看下,用 flat 方法怎么实现,请看下面的代码。
// 方法5
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.flat(Infinity);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]可以看出,一个嵌套了两层的数组,通过将 flat 方法的参数设置为 Infinity,达到了我们预期的效果。其实同样也可以设置成 2,也能实现这样的效果。
因此,你在编程过程中,发现对数组的嵌套层数不确定的时候,最好直接使用 Infinity,可以达到扁平化。
方法六:正则和 JSON 方法共同处理
我们在第四种方法中已经尝试了用 toString 方法,其中仍然采用了将 JSON.stringify 的方法先转换为字符串,然后通过正则表达式过滤掉字符串中的数组的方括号,最后再利用 JSON.parse 把它转换成数组。请看下面的代码。
// 方法 6
let arr = [1, [2, [3, [4, 5]]], 6];
function flatten(arr) {
let str = JSON.stringify(arr);
str = str.replace(/(\[|\])/g, '');
str = '[' + str + ']';
return JSON.parse(str);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]可以看到,其中先把传入的数组转换成字符串,然后通过正则表达式的方式把括号过滤掉。通过这个在线网站 https://regexper.com/ 可以把正则分析成容易理解的可视化的逻辑脑图。其中我们可以看到,匹配规则是:全局匹配(g)左括号或者右括号,将它们替换成空格,最后返回处理后的结果。之后拿着正则处理好的结果重新在外层包裹括号,最后通过 JSON.parse 转换成数组返回。
数组排序
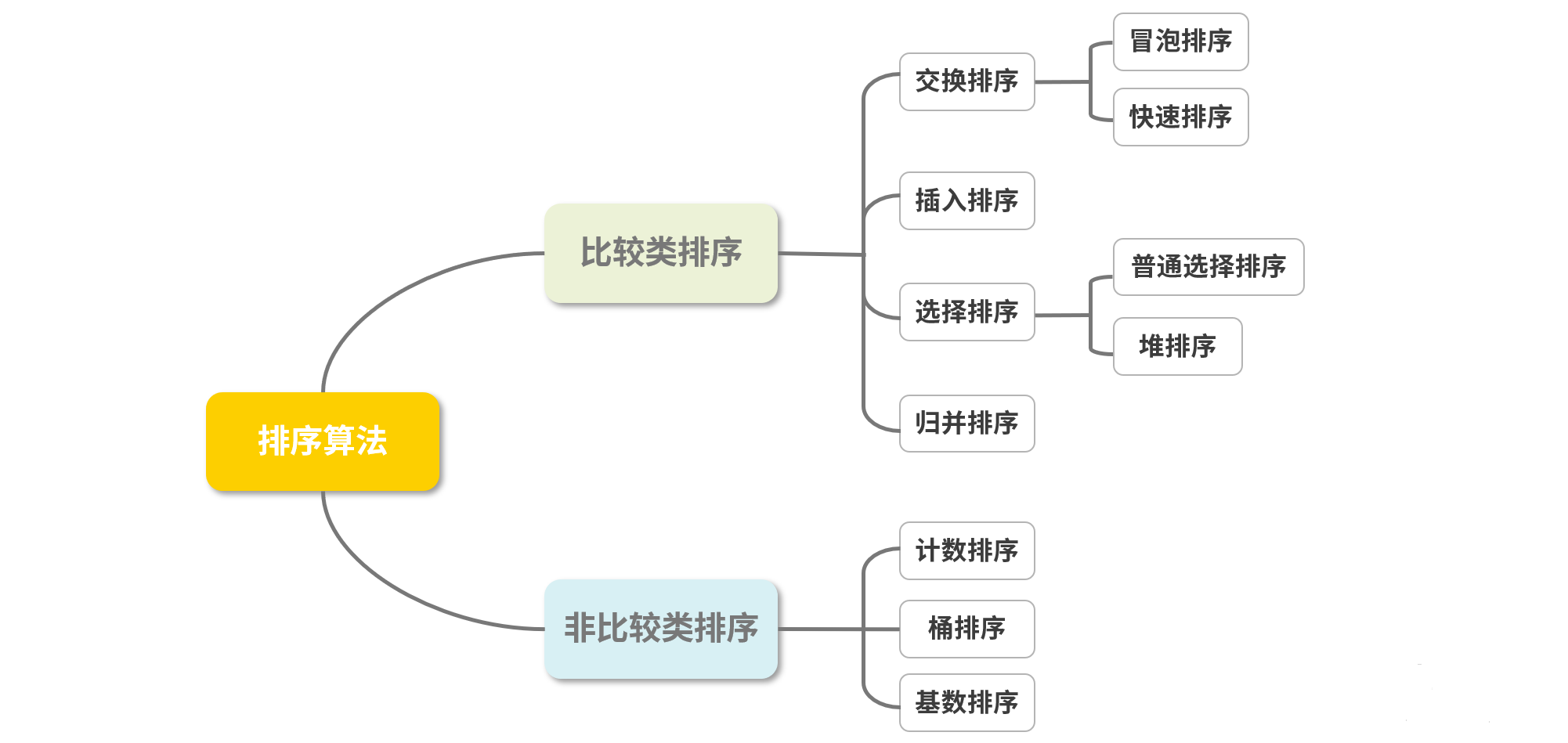
数据结构算法中排序有很多种,常见的、不常见的,至少包含十种以上。根据它们的特性,可以大致分为两种类型:比较类排序和非比较类排序。
- 比较类排序:通过比较来决定元素间的相对次序,其时间复杂度不能突破 O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
冒泡排序
冒泡排序是最基础的排序,一般在最开始学习数据结构的时候就会接触它。冒泡排序是一次比较两个元素,如果顺序是错误的就把它们交换过来。走访数列的工作会重复地进行,直到不需要再交换,也就是说该数列已经排序完成。请看下面的代码。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function bubbleSort(array) {
const len = array.length
if (len < 2) return array
for (let i = 0; i < len; i++) {
for (let j = 0; j < i; j++) {
if (array[j] > array[i]) {
const temp = array[j]
array[j] = array[i]
array[i] = temp
}
}
}
return array
}
bubbleSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]快速排序
快速排序的基本思想是通过一趟排序,将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可以分别对这两部分记录继续进行排序,以达到整个序列有序。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function quickSort(array) {
var quick = function(arr) {
if (arr.length <= 1) return arr
const index = Math.floor(len >> 1)
const pivot = arr.splice(index, 1)[0]
const left = []
const right = []
for (let i = 0; i < arr.length; i++) {
if (arr[i] > pivot) {
right.push(arr[i])
} else if (arr[i] <= pivot) {
left.push(arr[i])
}
}
return quick(left).concat([pivot], quick(right))
}
const result = quick(array)
return result
}
quickSort(a);// [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]上面的代码在控制台执行之后,也可以得到预期的结果。最主要的思路是从数列中挑出一个元素,称为 “基准”(pivot);然后重新排序数列,所有元素比基准值小的摆放在基准前面、比基准值大的摆在基准的后面;在这个区分搞定之后,该基准就处于数列的中间位置;然后把小于基准值元素的子数列(left)和大于基准值元素的子数列(right)递归地调用 quick 方法排序完成,这就是快排的思路。
插入排序
插入排序算法描述的是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,从而达到排序的效果。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function insertSort(array) {
const len = array.length
let current
let prev
for (let i = 1; i < len; i++) {
current = array[i]
prev = i - 1
while (prev >= 0 && array[prev] > current) {
array[prev + 1] = array[prev]
prev--
}
array[prev + 1] = current
}
return array
}
insertSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]从执行的结果中可以发现,通过插入排序这种方式实现了排序效果。插入排序的思路是基于数组本身进行调整的,首先循环遍历从 i 等于 1 开始,拿到当前的 current 的值,去和前面的值比较,如果前面的大于当前的值,就把前面的值和当前的那个值进行交换,通过这样不断循环达到了排序的目的。
选择排序
选择排序是一种简单直观的排序算法。它的工作原理是,首先将最小的元素存放在序列的起始位置,再从剩余未排序元素中继续寻找最小元素,然后放到已排序的序列后面……以此类推,直到所有元素均排序完毕。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function selectSort(array) {
const len = array.length
let temp
let minIndex
for (let i = 0; i < len - 1; i++) {
minIndex = i
for (let j = i + 1; j < len; j++) {
if (array[j] <= array[minIndex]) {
minIndex = j
}
}
temp = array[i]
array[i] = array[minIndex]
array[minIndex] = temp
}
return array
}
selectSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]这样,通过选择排序的方法同样也可以实现数组的排序,从上面的代码中可以看出该排序是表现最稳定的排序算法之一,因为无论什么数据进去都是 O(n 平方) 的时间复杂度,所以用到它的时候,数据规模越小越好。
堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质,即子结点的键值或索引总是小于(或者大于)它的父节点。堆的底层实际上就是一棵完全二叉树,可以用数组实现。
根节点最大的堆叫作大根堆,根节点最小的堆叫作小根堆,你可以根据从大到小排序或者从小到大来排序,分别建立对应的堆就可以。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function heap_sort(arr) {
var len = arr.length
var k = 0
function swap(i, j) {
var temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
function max_heapify(start, end) {
var dad = start
var son = dad * 2 + 1
if (son >= end) return
if (son + 1 < end && arr[son] < arr[son + 1]) {
son++
}
if (arr[dad] <= arr[son]) {
swap(dad, son)
max_heapify(son, end)
}
}
for (var i = Math.floor(len / 2) - 1; i >= 0; i--) {
max_heapify(i, len)
}
for (var j = len - 1; j > k; j--) {
swap(0, j)
max_heapify(0, j)
}
return arr
}
heap_sort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]从代码来看,堆排序相比上面几种排序整体上会复杂一些,不太容易理解。不过你应该知道两点:一是堆排序最核心的点就在于排序前先建堆;二是由于堆其实就是完全二叉树,如果父节点的序号为 n,那么叶子节点的序号就分别是 2n 和 2n+1。
你理解了这两点,再看代码就比较好理解了。堆排序最后有两个循环:第一个是处理父节点的顺序;第二个循环则是根据父节点和叶子节点的大小对比,进行堆的调整。通过这两轮循环的调整,最后堆排序完成。
归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function mergeSort(array) {
const merge = (right, left) => {
const result = []
let il = 0
let ir = 0
while (il < left.length && ir < right.length) {
if (left[il] < right[ir]) {
result.push(left[il++])
} else {
result.push(right[ir++])
}
}
while (il < left.length) {
result.push(left[il++])
}
while (ir < right.length) {
result.push(right[ir++])
}
return result
}
const mergeSort = array => {
if (array.length === 1) { return array }
const mid = Math.floor(array.length / 2)
const left = array.slice(0, mid)
const right = array.slice(mid, array.length)
return merge(mergeSort(left), mergeSort(right))
}
return mergeSort(array)
}
mergeSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]从上面这段代码中可以看到,通过归并排序可以得到想要的结果。上面提到了分治的思路,你可以从 mergeSort 方法中看到,通过 mid 可以把该数组分成左右两个数组,分别对这两个进行递归调用排序方法,最后将两个数组按照顺序归并起来。
归并排序是一种稳定的排序方法,和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好得多,因为始终都是 O(nlogn) 的时间复杂度。而代价是需要额外的内存空间。
push 方法的底层实现
为了更好地实现 push 的底层方法,你可以先去 ECMA 的官网去查一下关于 push 的基本描述(链接:ECMA 数组的 push 标准),我们看下其英文的描述,如下所示。
When the push method is called with zero or more arguments, the following steps are taken:
1. Let O be ? ToObject(this value).
2. Let len be ? LengthOfArrayLike(O).
3. Let argCount be the number of elements in items.
4. If len + argCount > 2^53 - 1, throw a TypeError exception.
5. For each element E of items, do
a. Perform ? Set(O, ! ToString(F(len)), E, true).
b. Set len to len + 1.
6. Perform ? Set(O, "length", F(len), true).
7. Return F(len).从上面的描述可以看到边界判断逻辑以及实现的思路,根据这段英文,我们将其转换为容易理解代码,如下所示。
Array.prototype.push = function(...items) {
let O = Object(this); // ecma 中提到的先转换为对象
let len = this.length >>> 0;
let argCount = items.length >>> 0;
// 2 ^ 53 - 1 为JS能表示的最大正整数
if (len + argCount > 2 ** 53 - 1) {
throw new TypeError("The number of array is over the max value")
}
for(let i = 0; i < argCount; i++) {
O[len + i] = items[i];
}
let newLength = len + argCount;
O.length = newLength;
return newLength;
}从上面的代码可以看出,关键点就在于给数组本身循环添加新的元素 item,然后调整数组的长度 length 为最新的长度,即可完成 push 的底层实现。
pop 方法的底层实现
Array.prototype.pop = function() {
let O = Object(this);
let len = this.length >>> 0;
if (len === 0) {
O.length = 0;
return undefined;
}
len --;
let value = O[len];
delete O[len];
O.length = len;
return value;
}其核心思路还是在于删掉数组自身的最后一个元素,index 就是数组的 len 长度,然后更新最新的长度,最后返回的元素的值,即可达到想要的效果。另外就是在当长度为 0 的时候,如果执行 pop 操作,返回的是 undefined,需要做一下特殊处理。
map 方法的底层实现
Array.prototype.map = function(callbackFn, thisArg) {
if (this === null || this === undefined) {
throw new TypeError("Cannot read property 'map' of null");
}
if (Object.prototype.toString.call(callbackfn) != "[object Function]") {
throw new TypeError(callbackfn + ' is not a function')
}
let O = Object(this);
let T = thisArg;
let len = O.length >>> 0;
let A = new Array(len);
for(let k = 0; k < len; k++) {
if (k in O) {
let kValue = O[k];
// 依次传入this, 当前项,当前索引,整个数组
let mappedValue = callbackfn.call(T, KValue, k, O);
A[k] = mappedValue;
}
}
return A;
}有了上面实现 push 和 pop 的基础思路,map 的实现也不会太难了,基本就是再多加一些判断,循环遍历实现 map 的思路,将处理过后的 mappedValue 赋给一个新定义的数组 A,最后返回这个新数组 A,并不改变原数组的值。
reduce 方法的底层实现
Array.prototype.reduce = function(callbackfn, initialValue) {
// 异常处理,和 map 类似
if (this === null || this === undefined) {
throw new TypeError("Cannot read property 'reduce' of null");
}
// 处理回调类型异常
if (Object.prototype.toString.call(callbackfn) != "[object Function]") {
throw new TypeError(callbackfn + ' is not a function')
}
let O = Object(this);
let len = O.length >>> 0;
let k = 0;
let accumulator = initialValue; // reduce方法第二个参数作为累加器的初始值
if (accumulator === undefined) {
throw new Error('Each element of the array is empty');
// 初始值不传的处理
for(; k < len ; k++) {
if (k in O) {
accumulator = O[k];
k++;
break;
}
}
}
for(;k < len; k++) {
if (k in O) {
// 注意 reduce 的核心累加器
accumulator = callbackfn.call(undefined, accumulator, O[k], O);
}
}
return accumulator;
}sort 方法的底层实现
如果要排序的元素个数是 n 的时候,那么就会有以下几种情况:
- 当
n<=10时,采用插入排序; - 当
n>10时,采用三路快速排序; 10<n <=1000,采用中位数作为哨兵元素;n>1000,每隔 200~215 个元素挑出一个元素,放到一个新数组中,然后对它排序,找到中间位置的数,以此作为中位数。
- 为什么元素个数少的时候要采用插入排序?
虽然插入排序理论上是平均时间复杂度为 O(n^2) 的算法,快速排序是一个平均 O(nlogn) 级别的算法。但是别忘了,这只是理论上平均的时间复杂度估算,但是它们也有最好的时间复杂度情况,而插入排序在最好的情况下时间复杂度是 O(n)。
在实际情况中两者的算法复杂度前面都会有一个系数,当 n 足够小的时候,快速排序 nlogn 的优势会越来越小。倘若插入排序的 n 足够小,那么就会超过快排。而事实上正是如此,插入排序经过优化以后,对于小数据集的排序会有非常优越的性能,很多时候甚至会超过快排。因此,对于很小的数据量,应用插入排序是一个非常不错的选择。
- 为什么要花这么大的力气选择哨兵元素?
因为快速排序的性能瓶颈在于递归的深度,最坏的情况是每次的哨兵都是最小元素或者最大元素,那么进行 partition(一边是小于哨兵的元素,另一边是大于哨兵的元素)时,就会有一边是空的。如果这么排下去,递归的层数就达到了 n , 而每一层的复杂度是 O(n),因此快排这时候会退化成 O(n^2) 级别。
这种情况是要尽力避免的,那么如何来避免?就是让哨兵元素尽可能地处于数组的中间位置,让最大或者最小的情况尽可能少。这时候,你就能理解 V8 里面所做的各种优化了。
function ArraySort(comparefn) {
CHECK_OBJECT_COERCIBLE(this,"Array.prototype.sort");
var array = TO_OBJECT(this);
var length = TO_LENGTH(array.length);
return InnerArraySort(array, length, comparefn);
}
function InnerArraySort(array, length, comparefn) {
// 比较函数未传入
if (!IS_CALLABLE(comparefn)) {
comparefn = function (x, y) {
if (x === y) return 0;
if (%_IsSmi(x) && %_IsSmi(y)) {
return %SmiLexicographicCompare(x, y);
}
x = TO_STRING(x);
y = TO_STRING(y);
if (x == y) return 0;
else return x < y ? -1 : 1;
};
}
function InsertionSort(a, from, to) {
// 插入排序
for (var i = from + 1; i < to; i++) {
var element = a[i];
for (var j = i - 1; j >= from; j--) {
var tmp = a[j];
var order = comparefn(tmp, element);
if (order > 0) {
a[j + 1] = tmp;
} else {
break;
}
}
a[j + 1] = element;
}
}
function GetThirdIndex(a, from, to) { // 元素个数大于1000时寻找哨兵元素
var t_array = new InternalArray();
var increment = 200 + ((to - from) & 15);
var j = 0;
from += 1;
to -= 1;
for (var i = from; i < to; i += increment) {
t_array[j] = [i, a[i]];
j++;
}
t_array.sort(function(a, b) {
return comparefn(a[1], b[1]);
});
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}
function QuickSort(a, from, to) { // 快速排序实现
//哨兵位置
var third_index = 0;
while (true) {
if (to - from <= 10) {
InsertionSort(a, from, to); // 数据量小,使用插入排序,速度较快
return;
}
if (to - from > 1000) {
third_index = GetThirdIndex(a, from, to);
} else {
// 小于1000 直接取中点
third_index = from + ((to - from) >> 1);
}
// 下面开始快排
var v0 = a[from];
var v1 = a[to - 1];
var v2 = a[third_index];
var c01 = comparefn(v0, v1);
if (c01 > 0) {
var tmp = v0;
v0 = v1;
v1 = tmp;
}
var c02 = comparefn(v0, v2);
if (c02 >= 0) {
var tmp = v0;
v0 = v2;
v2 = v1;
v1 = tmp;
} else {
var c12 = comparefn(v1, v2);
if (c12 > 0) {
var tmp = v1;
v1 = v2;
v2 = tmp;
}
}
a[from] = v0;
a[to - 1] = v2;
var pivot = v1;
var low_end = from + 1;
var high_start = to - 1;
a[third_index] = a[low_end];
a[low_end] = pivot;
partition: for (var i = low_end + 1; i < high_start; i++) {
var element = a[i];
var order = comparefn(element, pivot);
if (order < 0) {
a[i] = a[low_end];
a[low_end] = element;
low_end++;
} else if (order > 0) {
do {
high_start--;
if (high_start == i) break partition;
var top_elem = a[high_start];
order = comparefn(top_elem, pivot);
} while (order > 0);
a[i] = a[high_start];
a[high_start] = element;
if (order < 0) {
element = a[i];
a[i] = a[low_end];
a[low_end] = element;
low_end++;
}
}
}
// 快排的核心思路,递归调用快速排序方法
if (to - high_start < low_end - from) {
QuickSort(a, high_start, to);
to = low_end;
} else {
QuickSort(a, from, low_end);
from = high_start;
}
}
}从上面的源码分析来看,当数据量小于 10 的时候用插入排序;当数据量大于 10 之后采用三路快排;当数据量为 10~1000 时候直接采用中位数为哨兵元素;当数据量大于 1000 的时候就开始寻找哨兵元素。