
APM
很多公司已经选择 Node.js 来承接服务端(BFF层),但由于此类应用的编写人员大部分都是前端工程师,对一个服务端应用 的部署上线,监控,高可用等概念并不了解,遇到线上问题常常无从下手。
本篇文章从应用监控,应用上线部署,日志收集,高可用实施与安全问题防范等各个方面展开讲述,学习 BAT 级别的公司如何让一个Node.js 应用稳定的支撑大规模线上业务。
核心概念
在日常工作中我们一般如何排查问题呢?例如当产品中的按钮无响应,你怎么排查问题?对于一个前端工程师来说,我们通常会查看浏览器是否有报错,点击按钮时是否触发了JS异常,然后检查接口是否正确返回数据,接口是否响应。如果接口报错,我们还要去检查接口内逻辑是否有问题。
这就是一个普通的排查思路,从前端代码到接口最后到服务本身。但是如果作为一个全栈工程师,真实场景遇到的难度会更大。例如:
- 运营商的问题,比如用户的运营商劫持js,导致前端代码出错。
- CDN的某个节点缓存出现问题,导致一个老版本的js上线了。
- 用户的机器浏览器版本正好有一个bug,代码触发了这个bug。
- 服务所在的某个机房某台机器故障了,导致服务挂掉了。
- 服务依赖的一个第三方服务,欠费了。
所以说业内为了解决这个问题,提出了APM这个词,APM(Application Performance Management)是监控服务的一套技术手段,致力于监控并管理程序的性能和可用性。它主要包含以下部分:
- 终端用户体验:反映用户的真实体验
- 应用架构映射:从监控逆向分析出真实链路
- 应用事务分析:能从一个唯一的线索(用户)找出整条事务或操作
- 深度应用诊断:精准定位问题
- 分析与报告:提供实时准确的大数据查询和可视化
组成部分
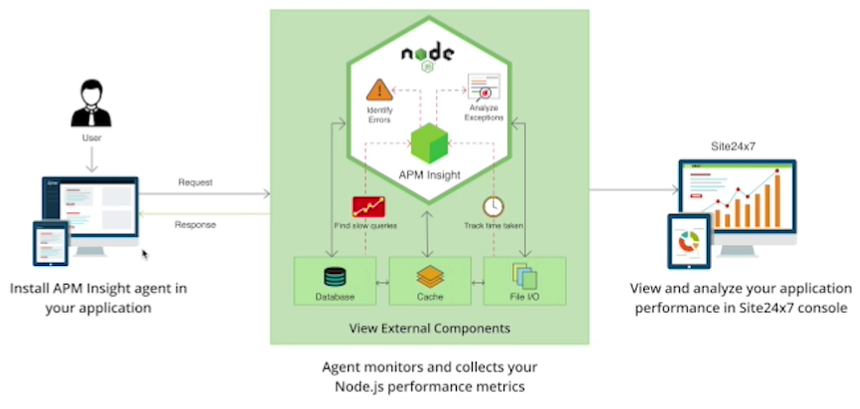
APM包括Agent,Monitor及Dashboard/Console,Agent用于上报数据,Monitor用于收集数据,Dashboard用于展示数据。
APM形态
- 服务器性能指标监控:对服务依赖的硬件性能进行监控,如CPU、内存、硬盘容量。监控服务器性能指标的实时值,用于出紧急问题时及时报警。监控历史趋势,可以观察每天的访问情况以及对异常点进行分析。服务器性能指标监控是最基本且最重要的APM,他就像身体的各项指标,一旦出现异常都是比较严重的问题。
- 服务监控:对提供的服务进行监控,检测服务的情况,如请求书、响应数、成功率。检测服务的热点,异常波动。检测服务来源,调用方分布。
- 错误/异常监控:对报错或异常进行监控,一般需要主动上报。需要提供大量上下文信息才有意义,如当时的URL,错误堆栈,甚至用户信息。
- 日志收集:对服务的所有情况进行记录,日志是必不可少的。不管是业务本身,还是访问记录,都需要尽可能记录日志。日志的查询分析很困难,所以APM一般都有日志收集和分析的能力。日志会占用大量硬盘空间,所以需要定期清除,清除掉就很难查到问题了。日志是服务器中最重要的证据,打日志就像前端的打点,因此日志一定要记录有价值的信息,如时间、关键指标、traceId。
- 依赖监控:对服务的依赖进行监控,如数据库、缓存、外部服务。几乎所有的响应缓慢问题均由依赖导致。依赖监控也是比较大范围的监控,只能发现问题,很难跟服务本身关联起来。
- 分布式事务追踪:真实场景,一个服务从发起到完成,要经历很多的节点。传统的APM工具只能检测一个或多个节点的情况,无法串起来。分布式事务追踪可以通过一个ID就可以查询到一次请求的全链路情况。
- 代码级监控分析(Profiling):一般利用自动化的代码插桩技术,获取Node.js进程内方法的调用链路,可以查看调用栈上的总执行时间和每个方法占的百分比。结合V8 Profiling,查看可能出现的内存泄漏情况。